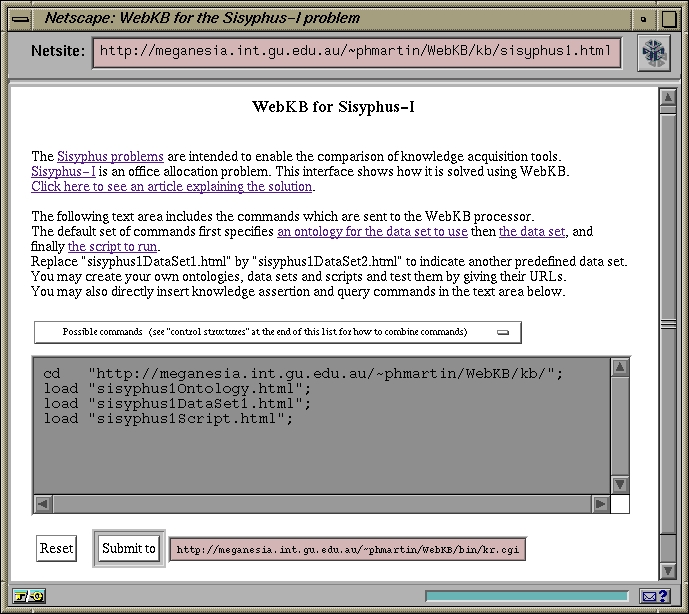
Figure 1: An interface for solving the Sisyphus-I problem with WebKB
Philippe Martin and Peter Eklund
Griffith University,
School of Information Technology,
PMB 50 Gold Coast MC, QLD 9726 Australia
Tel: +61 7 5594 8271; Fax: +61 7 5594 8066;
E-mail: pm .@. phmartin dot info
This article has been accepted - and published - at the
Sisyphus-I
track of ICCS'99,
7th International Conference on
Conceptual Structures, July 12-15, 1999.
Slides.
This article explains how we have used
WebKB [1]
- our Web-accessible and Conceptual Graph (CG) based knowledge acquisition
and annotation tool - to provide
a
solution and an interface [2] to solve the
Sisyphus-I
office allocation problem [3], a problem intended to enable the comparison
of knowledge acquisition tools.
We have exploited the WebKB CG assertion/query commands and script language
FC (For-Control) to provide two procedural solutions to the problem.
One of them is recursive and handles backtracking. However, since
we found that the problem can be also solved using a simple and direct
script, we present this direct script in this document.
The script, the data set and the ontology (i.e.
structured set of types) used by both may be stored in different Web-accessible
documents, the URLs of which may be sent via a simple interface to
the WebKB processor (which is a
CGI server [5]) in order to
solve the problem.
Users may also provide their own files to test their solutions,
or use their own data sets.
As an example of WebKB flexibility, the URL of this document (its HTML
version) could be sent to the WebKB CGI server to solve the problem
since this file includes (and comments on) a script, a data set and the
ontology they rely on. Such a feature is called "active/virtual document
support" in the hypertext litterature [6].
To allow an easy comparison of our tool with other knowledge acquisition tools we have followed the requirements and protocols given in the Sisyphus-I problem description [1] rather than invented our own solution (this was a proposed alternative). However, as in Brian Gaines' solution [3], we have added an additional constraint: in the data set the user may represent the fact that some offices must be allocated to some given employees. Thus, the office allocation script may still be best exploited in under-determined situations. Similarly, the user may modify the data set (or the script itself) to cope with situations that the script found over-determined (e.g. some offices may be added or some constraints for sharing offices relaxed).
The data set gives the characteristics of the offices, and employees to place within them, with commands for asserting individuals and CGs, and using the ontology the script relies on. Indeed, if the user wants to modify the ontology, s/he must also modify the script appropriately. The next subsection explains why a textual interface is used for the ontology, data set and script, while the next three subsections respectively present the content of an ontology, a data set and a script.
Though WebKB proposes a CG graphic editor, we mainly use a linear notation to assert or query types, instances or CGs, and insert these commands in scripts or any other document (e.g. this article). There are three main reasons for this. First, we find it easier and quicker to use a good text editor and an interpreter for building and exploiting a CG base than use the WebKB graphic editor (or any other CG graphic editor we have tried until now). Besides, the linear notation and script language in WebKB provide more features and combination possibilities. Second, we think a linear notation is as good for readability as a graphic notation at least for tree-like structures (which is the case of all the structures we had to deal with to solve the Sisyphus-I problem). Third, since the linear notations take less place on the screen than graphic notations, a user may visually compare more CGs or more information including CGs (thus, for example, it is easier for a user to handle and debug programs including CGs). For these reasons, and to remove ambiguities, in the following sections we also prefer to present the ontology, data set and script entirely in the form they are accepted by the WebKB processor rather than using any graphical form. It should however be noted that WebKB can handle HTML documents where type declarations or CG assertions are hidden behing images (more exactly, stored in the "alt" field of the "img" tags) and can present these images to the user when the types or CGs are results of queries.
Figure 1 shows an HTML&Javascript interface which sends an ontology, a data set and a script (plus possibly other commands) to the WebKB processor. Figure 2 shows the window which pops up to display the results of the execution of the ontology, data set and script by the WebKB processor.
Figure 1: An interface for solving the Sisyphus-I problem with WebKB
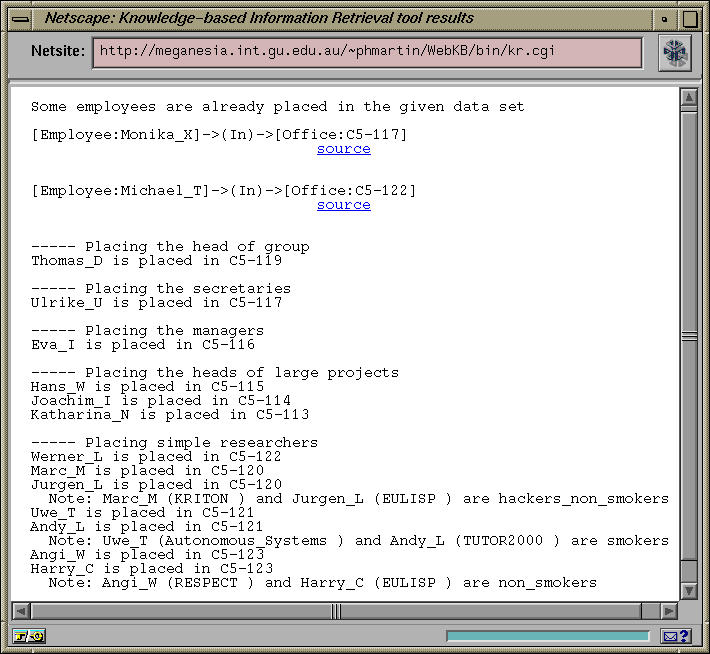
Figure 2: Results from the WebKB processor in answer to the queries in Figure 1
The ontology below is composed of concept types, e.g. Something and Location, and relation types, e.g. Agent and Project. Before explaining the syntax, let us note that we had three goals in mind when designing it. By increasing order of importance: minimising the ontology length (only types used by the script are declared), minimising the data set length (to keep it simple and ease the updates), and maximising the efficiency of the script.
|
The first line declares the concept type Something and four subtypes. The syntax is close to Sowa's usual linear notation for ordering types (Sowa, 1984). An extra feature is the pair of parenthesis around the subtypes which means that they belong to a same partition of exclusive types, i.e. they must not have common subtypes. WebKB enforces that property by refusing to create new types which would violate it. Since in WebKB - as in Sowa's CG model - an individual (i.e. an object conforming to a type) is instance of (is conforming to) one and only one type, exclusive types cannot have common instances. (Two non-exclusive types may have common instances if one specializes the other).
The second line declares Project and Research_group as non-exclusive subtypes of Organisation, and the third line declares Smoker and Non_smoker as two exclusive subtypes of Person but not exclusive with their sibling Employee.
The types Small_central_office, Small_and_not_central_office, Large_central_office and Large_and_not_central_office have been introduced to simplify the data set and the script: thus, such size and location properties are declared or handled via instance assertion/query commands instead of CG assertion/query commands.
A similar representation could be used for storing the facts that some researchers smoke or hack, but in such a case there is no gain in simplicity compared to the use of CGs since a lot of "unnatural" types have to be declared and handled, e.g. types such as Hacker_non_smoker and Non_hacker_non_smoker, and a type for each project. Instead, the script generates the sets of individuals which would be instances of such types.
Conversely, some users may regret not to be able to also use CGs to represent the size and location properties of offices (i.e. some users would use types while others would use CGs). To allow this, WebKB would need to classify each individual under the adequate (most specialized) types of the ontology according to the way they are used in CGs. Such instance classification features are common in terminological logics systems, e.g. LOOM [7], and some object-oriented systems but not in CG systems which instead focus on CG classification, e.g. Peirce [8].
Another solution would be to represent most of properties of individuals using CGs, i.e. using conceptual relations types such as Secretary or Manager to relate a project to its employees, instead of using "instance-of" relations. This solution would need to introduce many relation types in the ontology and therefore many queries on individuals to the script but could be useful if there were more than one research group to handle. In the given protocol, only the research group HQT is considered and this information is not used for allocating offices. Therefore, to simplify the data set and script, and show the exploitation of both CGs and instance relations, we have not chosen that solution.
To represent the fact that some researchers smoke or hack, the process types Smoke and Hack are introduced.
As indicated above, a minimal number of relations have been introduced: Agent, Project, In and Near. Their signatures are given between parenthesis, e.g. a relation of type Agent relates a concept of type Process to a concept of type Person. WebKB checks that the signatures are verified each time a CG is created.
The documentation of WebKB languages [9] describes additional ways to build an ontology, e.g. via type definitions.
Below is the data set referred to in Figure 1.
|
The first line declares C5-117 and C5-119 as instances of the concept type Large_central_office. The other offices are similarly declared in the next two lines.
The neighbourhood of the offices is represented using conceptual relations of type Near. Since WebKB only handles oriented relations, a relation of type Near is used in both direction between each pair of neighbor offices.
Each project and employee is declared as an instance of Project or the relevant type of employee. Then, for each simple researcher, a CG is used to represent the membership of the employee to a project and if s/he uses to smoke or hack. Such facts are represented only for simple researchers since, according to the protocol, these facts are only used when offices have to be shared, and it seems that only simple researchers share offices. The requirements are ambiguous on this point. For the sake of simplicity, in the script presented below, only simple researchers can share offices. However, the representation of the smoking and hacking habits of all researchers wouldn't lead the script to false results but rather slow its execution.
Finally, two CGs are used to represent the facts that Michael T. must be in office C5-122 and Monika X. in office C5-117.
To solve the Sisyphus-I problem, we first came up with a recursive solution [10] that handles backtracking by deleting CGs representing office allocations. However, we then realised that since the employees must be placed in a precise order (head of group, secretaries, managers, heads of large projects and finally simple researchers), backtracking is useless if (i) only simple researchers share offices, (ii) the head of group must have a large office whenever possible (even if because of this allocation, there are insufficient large offices for simple researchers), and (iii) offices may be left empty while simple researchers share large offices. This seems to be the case according to the protocols and requirements. Though additional constraints may voluntary be taken into account (such as the fact that some offices may be pre-allocated), we have preferred to take into account the above three hypothesis in order to present a script much simpler and more efficient than the recursive one. Below, we present each function of this simple script.
Below is the main function. The WebKB scripting language is a language of commands simpler but similar to the C-shell on Unix. Control structures and pipes are used for combining commands. Variables need not to be declared and are global. However, function parameters are local to the function, and as a convention, the first letter of variables which are used in different functions is uppercase. The value of variables or function parameters can only be a string or a real and is accessed by prefixing the variable with the character '$'. The function "main" is not a special function as in C, it has to be explicitly called such as any other function.
|
The function main() shows that there is a different function for placing each kind of employee. Each of these functions are called in the order recommended by the expert and when necessary. To simplify and avoid backtracking, the script tries to place simple researchers together and then place the remaining employees alone. These remaining employees may be simple researchers or employees of a kind not included in the protocol.
Before trying to place employees, the function check_if_already_placed_employees() is called to print and take into account the employees which, in the data set, are already placed in an office.
The command "spec" searches the specializations of types or CGs.
The results of a command (e.g. "spec") are printed unless it is followed by a
pipe ('|'). In that case, the (possibly empty) list of results is
automatically added to the parameters of the following command (if the results
are CGs, the names of the CGs are added to the parameters).
If "spec" has a CG for parameter, it searches specializing CGs.
However, if a question mark ('?') in the CG specifies that only some kinds of
instances are to be presented (as in "spec [Employee:?]->(In)->[Office]"),
the result is the list of instances belonging
to the retrieved specializing CGs. A result is not added twice to the
result list. This is important for loops iterating on a result list.
If "spec" has only a type for parameter, it will search for subtypes.
If "spec" has as parameters a type, a semicolon and a question mark
(as in "spec Employee : ?"), it searches for the instances of the
type (this includes the instances of the type subtypes).
The command "subtract" takes two lists of white-separated strings as parameters, and returns as result the elements of the first list except those which appear in the second list. Thus, in the function check_if_already_placed_employees(), the global variable Employees_to_place is initialized to the list of employees not already placed in the data set.
Below are the functions related to the placement of the head of group. The first two are simple models for the functions placing the other kinds of employees, while place_employee_in() is actually reused by all of them.
|
The function possible_to_place_the_group_head() successively tries to place the head of group in each of the four exclusive kinds of offices, by decreasing order of preference: large and central office, small and central office, large and not central office, large and not central office. This order is not given by the protocol which only recommends the placement of the head of group in a large central office, but seems natural and suppresses the need for backtracking (provided that only simple researchers may share offices and the head of group must have a large office whenever possible).
The function possible_to_place() tries to place a given employee in the first unoccupied office which is an instance of the given kind of office. The script stops if it cannot find a way to place an employee.
The function place_employee_in() creates a CG for storing the allocation of an employee in an office. The name of the CG is built by concatening the name of the employee and the name of the office. Then, the employee is removed from the list of employees to place via the command "subtractFrom" which is similar to "subtract" except it takes a variable referring to a list as first argument, uses its value and then affects it with the result list.
Secretaries, managers and heads of large projects need to be placed in certain kinds of office and nearest possible to the office of the head of group. This is what the next function does. First, the offices adjacent to the office of the head of group are tested. Then, the distance is progressively augmented via a loop which adds a new relation of type Near to the query CG at each of its step.
|
Secretaries must be placed nearest to the head of group and if possible in the same office. Thus, the following functions first search the offices containing a secretary and test if the office is not fully occupied. To simplify, we have considered that a large office may contain only two employees. This is in accordance with the protocol.
|
The functions for placing the managers and the heads of large projects are similar except that the heads of large projects need not have a central office. In both cases, small offices are first tried. Thus, backtraking is not necessary, provided that only simple researchers may share an office.
|
Below are functions which allocate large offices to researchers. Again, our assumptions are that (i) only simple researchers may share offices, (ii) offices may be left empty while simple researchers share large offices, (iii) large offices are twin offices.
According to the "note 2" in the requirements, three constraints govern the
sharing of offices:
(i) smokers and non-smokers should not be put together into an office,
(ii) coworkers that work on related subjects can share an office,
(iii) researchers in same projects are (if possible) not sharing an office.
The terms "related subjects" are quite ambiguous since no "subject" is listed
in the description of the members of YQT (in section 2.1.1.). However,
part 8a of the protocol, which explains why Werner L. and Jurgen L. are placed
in a same office, gives an indication: "They do not work in the same project,
but they work on related subjects". Since Werner L. and Jurgen L. do not
work with each other but are both hackers, it seems that the term "subject"
refers to the fact that an employee hacks or not. Part 9a of the
protocol, which explains why Marc M. and Angi W. are placed in a same office,
supports this interpretation: "Marc is implementing systems, Angi isn't. This
shouldn't be a problem".
Since we want to have a simple and non-recursive script, the script cannot place simple researchers alone in offices and then, when all offices are occupied, put the remaining researchers with already placed simple researchers: indeed, to best satisfy the sharing constraints, some already placed employees would have to be moved. Furthermore, it would then also be necessary to distinguish the employees that have been placed by the user from the employees that have been placed by the script. Therefore, our solution is to search and place pairs of simple researchers that satisfy the sharing constraints, and then, if necessary, progressively relax the constraints while there are still simple researchers to place and places in large offices. The function try_to_place_pairs_of() perform the search and copes with the fact that one researcher of a suitable pair may have already been placed by the user (and indeed there is no problem when the user has placed two researchers in a same office). When necessary, this function also relaxes the third constraint: "researchers in same projects should rather not share an office".
The function try_to_place_simple_researchers_by_pairs() searches the instances of the four exclusive types of researchers who are suitable to share an office: smoker hackers, smoker non hackers, hacker non smokers, non hacker non smokers. When necessary, this function relaxes the constraint of "related subjects" (hacking habits).
The command "subtractFirstFrom" is similar to "subtractFrom" except that it has no second argument: the first element of the referred list is removed from it and returned as a result.
|
|
The next function tries to place employees that are not yet placed, alone in an office . These are simple researchers or employees of a kind not foreseen by the protocol.
|
We have not tested our script theoretically but empirically. The reader is welcome to test it by visiting our Web-accessible Sisyphus-I interface [2] (http://www.webkb.org/kb/webkb1/sisyphus1.html) and adding queries or modifying the used data set or even the script. To give another test example, let us consider the second problem Katharina N. has left and Christian I. joined the group. Christian I. is a simple researcher who smokes, hacks and works in MLT. Below are the differences between the first data set and a data set for the second problem. The new results provided by WebKB follow.
|
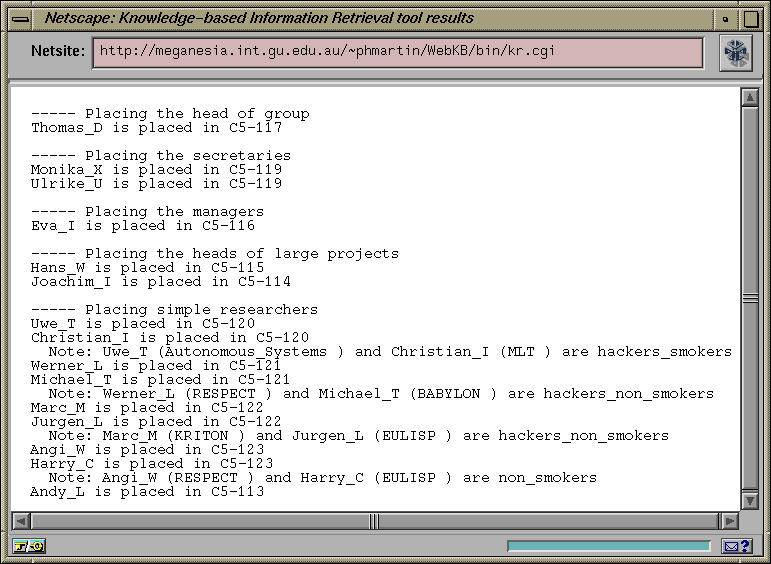
Figure 3: Results from the WebKB processor for the second data set
Our Web-accessible and script language based approach has several advantages. First, a user can easily test our programs or query our files and create new ones. As opposed to graphic interfaces, the linear notation for CGs and the script language allow the user to quickly create knowledge assertions or queries and also combine them to build complex queries or programs. We think the script discussed in this article is relatively readable and intuitive, at least for persons used to CGs and either the C, C-shell or shell language. Though they are not directly relevant to the Sisyphus-I problem, let us note that WebKB also proposes simpler knowledge representation notations [9] (a frame-oriented CG linear notation and a form of formalized English) and constructs (e.g. based on HTML constructs) in order to ease and improve the readability of knowledge in documents, the indexation of documents with knowledge, and finally the retrieval or generation of knowledge or parts of documents.
It seems interesting to compare our solution with Brian Gaines' solution [4] since the article that describes it is Web-accessible along with the Sisyphus-I problem description and shows how KSSn - a knowledge representation server with KL-ONE-like term subsumption representation capabilities and a graphic language - is exploited. (However, the solution itself is not Web-accessible for testing).
Our representation of the ontology and data set is relatively similar to the one with KSSn, though a bit less precise since WebKB does not have constructs to represent and check (i) the number or maximum number of concepts related to a concept of a certain type via a relation of a certain type, and (ii) the fact that all the concepts related via a relation of a certain type to a certain concept have been represented. (However, these constructs would not have been useful to us for the Sisyphus-I problem). Besides, our linear notation may also appear less intuitive than the visual language used for KSSn.
The real difference is in the problem-solving description. Brian Gaines'
solution uses 18 rules which rely on a rule-based system in KSSn. Each rule
adds relations to some objects and a truth maintenance system
handles the propagation of the consequences of those new assertions.
The solution, which is based on the simultaneous search for
ready-to-be-allocated offices (8 rules) and ready-to-be-triggered office
allocation tasks (7 rules), is certainly ingenious and short but we found it
quite difficult to understand and, despite the trace examples, still do no
know what is exactly going on and how all the rules combine.
As a small stand-alone example, the reader can look at the last 3 other rules
which
search for an unoccupied office nearest to the office of the group of head.
Besides, the solution does not seem to be as complete as ours because the
8 rules which decide to whom an office should be allocated, only follow the
expert protocol and do not generalize it. Here are these 8 rules in
natural language and declining priority:
- if an office is large and central and the head of group is without an
office, suggest the allocation;
- a large office already occupied by a secretary should be allocated to
another secretary;
- a large office near the head of group is suitable for the secretaries;
- a single office near the head of group is suitable for the manager;
- a single office near the head of group is suitable for the heads of large projects;
- a large office with a smoking researcher occupant should be allocated to
another smoking researcher;
- a large office should be allocated to smoking researchers;
- a large office with a non-smoking researcher occupant should be allocated
to another non-smoking researcher;
- a large office should be allocated to non-smoking researchers.
Therefore, for example, how are the head of group and secretaries placed
if there is no large offices? Similarly, how are the manager(s) and
heads of large projects placed if there is no available single offices?
In our procedural approach, the underlying rules of office allocation are quite clear, the order of execution is explicit and the constraints are progressively relaxed in each allocation case.
The question of efficiency is complex and is not really important in this
problem when the data are as small as those in the given examples. Though our
approach includes a lot of searches for specializations of types or CGs and
though WebKB is not optimised for these searches, it loads itself (6Mb), gets
the files (ontology, data set and script) and solves the problem in only a
second or two when transmission latency on the Web is minimum (and about
two or three seconds when the URL of this article is sent to WebKB instead of
URLs for separate small files).
Generally speaking, rule-based approaches are often said to be slower to
run but easier to implement than procedural approaches.
It is true in this case that we took a lot of time to implement our
procedural solutions (recursive and direct) but this is mainly for the
following reasons:
(i) the Sisyphus-I problem is under-specified so we had many alternatives to
explore,
(ii) this was the first time we developed a genuine (long) program with CGs
as data structures (again, there were many alternatives),
(iii) we had to add some code in WebKB for handling some special constructs
and commands (e.g. for supporting functions and the commands subtract,
subtractFrom and subtractFirstFrom).
More details are given in the next section.
Regarding the second above point, our initial problem was to find an elegant
way to deal with the absence of what are called objects in object-oriented
languages or structures in classic procedural languages. For example in those
languages, employees could simply have been represented by objects of type
Employee with the attributes (or slots) name, role, project, smoker,
hacker and works-with, i.e. exactly as they are described
in the Sisyphus-I problem description. We could have used conceptual relations
for representing such attributes but:
(i) CGs such as [Simple_researcher:Uwe_T]- { (Smoker)->[Boolean:yes]; (Hacker)->[Boolean:yes]; }
sound artificial (why using CGs instead of an object-oriented language for such
representations?),
(ii) testing if a researcher smokes or not still involves a search for
specializations which is not a quick or elegant way to test an object attribute, e.g.:
spec "[Simple_researcher:$o]->(is_a_smoker)->[Boolean:?]" | set is_a_smoker.
Consequently, our initial problem was to find a rationale for deciding what
to represent in the type hierarchy and what to represent with CGs. We discussed
the results in section 1.2.
Though our combination of searches for specializations and "for" loops seems quite natural, it remains that the implementation of a solution in a classic object-oriented language would have been quite easy for the Sisyphus-I problem and, especially if the language is compiled, more efficient than our solution. For large-scale problems, this is an issue.
The WebKB processor has been developed in C on top of the CG workbench CoGITo [11]. The CG workbench Peirce was also used at one stage but this configuration was slower since Peirce has to be exploited as a separate process. The W3C library [12] (5 Mb over the 6Mb of WebKB) is reused to access Web files. The interfaces for WebKB have been written in HTML and Javascript [13].
The way we solved the Sisyphus-I problem did not draw much upon our
experience in CGs or knowledge acquisition but rather in programming!
Indeed, even though we have worked on knowledge modelling, visualisation
and ordering using CGs for more than 5 years (because CGs are a rather
general and intuitive knowledge representation language which exploits type
ordering), we think solving the Sisyphus-I problem with WebKB did not
required such an experience with CGs:
(i) the Sisyphus-I knowledge structures are already overt (as Brian Gaines
notes) and very simple (only type ordering and simple existential CGs are
necessary);
(ii) the protocol and the requirements strongly suggest a certain order in
the allocation tasks (thus, a procedural solution comes naturally),
(iii) WebKB does not have a rule-based system but it has a scripting language
and commands for declaring, defining, ordering, asserting, searching and
joining types, individuals and CGs.
Thus, for us the Sisyphus-I problem was not a knowledge acquisition
problem (we did not follow a methodology or reused an ontology)
but a programming problem: how to use the WebKB commands to find an elegant
and (if possible) efficient solution? The advantage we had as designers of
WebKB is that we already knew well the WebKB commands, and that we could add
other ones when necessary.
As required, we now give an approximate schedule for the tasks that led to the implementation of our solution. We use a "day" or "half a day" as units of time, half a day being 3 to 4 hours. Since we had other tasks to do, these units were often split over several actual days.
First, we read the Sisyphus-I problem description and, to better understand what should or could be done, the associated Web-accessible article of Brian Gaines. This took at least a day since the article is long and, as we pointed out, the meaning and combination of the rules complex to understand.
Then, during half a day, we tested a translation of some of the representations used in Gaines' article into CGs. The result was not really satisfying since sets and value constraints were used, and though they can be represented in CGs, these constructs cannot not be enforced by WebKB. Another half day was spent to decide if a classification and agenda mecanism similar to the one described in the article was worth simulating with the WebKB script language. We found it much simpler to implement the rules via functions and use recursivity to handle backtracking.
We first implemented the interface in about half a day.
We designed and entered the bulk of the recursive script (and the relevant ontology and data set for it) in a day or a day and a half. Two and a half days were then devoted to progressively debug and refine the script, intertwined with two days for adding a few things to the WebKB code, mainly functions (with parameters, instruction return, etc.) and the command "subtract".
By then we understood much better the protocols and the requirements. We had realised that a solution without backtracking would be simpler, more efficient and nearly as complete. It took us a day to design and enter the bulk of the direct script, half a day to add the commands "subtractFrom" and "SubtractFirstFrom", and two days to progressively debug and refine the script.
It therefore took us about 12 days to come up with the solution described above. However, 4 days would have been sufficient if the problem description had been more detailed and explicit, and if new WebKB commands had not to be inmplemented. Here could have been the schedule: one day to read the documentation and implement the interface, and three days to design, refine and debug the direct solution. We also expect to be quicker for other Sisyphus problems since we now better understand how to write genuine programs with CGs and the WebKB language.
The documentation is ambiguous and incomplete on the rules to follow.
Here are some examples we noted earlier.
Can the head of group, manager(s) and heads of large projects share their
office if necessary? (The requirements just note they are "eligible for
large offices"). May offices be left empty while simple researchers share large
offices? Are all large offices twin offices? Does the expression
"coworkers that work on related subjects" mean "employees that have
the same hacking habits"?
Here are some other points noted by Brian Gaines.
What should be done to place the head of group if there is no large central
office?
What should be done to place the secretaries if there is no office close to
the head of group?
What should be done if there are several secretaries, not all of whom can be
close to the head of group?
What should be done if one secretary is a smoker and another not?
What should be done to place the manager if there is no single office close?
What should be done if the head of group and secretariat are split?
What should be done if there is more than one manager?
We made a decision on each of the above points. Since other people may make other decisions, the documentation ambiguity and incompleteness may make it harder to compare the possibilities of different knowledge acquisition tools. As the previous section shows, the ambiguity and incompleteness of the problem does not give more freedom but creates more work to the knowledge engineer.
We do not think the application domain of Sisyphus-I is very appropriate for the comparison of knowledge acquisition tools (CG-based or not) since (i) the problem has a natural procedural solution and the ontology is small and fixed (i.e. it is not updated interactively by the users), therefore classic object-oriented language are adequate to solve it, (ii) as opposed to a lot of real-world problems, efficiency is not an issue (it is unlikely that a lot of employees have to be placed and that the problem solver has to be run frequently).
Conversely, this problem allowed us to show that CGs may be used and mixed in a script language to elegantly solve a problem which has a procedural solution.
Though WebKB was not developped to solve problems but rather to
ease the modeling, organisation, retrieval and generation of knowledge or
parts of documents indexed by knowledge, this application
showed the generality and interest of its features:
- the integration of CG search/handling commands and a script language;
- the insertion of commands (e.g. knowledge assertions) inside documents;
- its Web-accessibility and the exploitation of Web-accessible documents.
To our knowledge, procedural languages have not been associated with CGs
or description logics. The use of scripts and their insertion in documents
has a broad range of applications and is common in the hypertext litterature
but WebKB seems to be the first Web-based knowledge-oriented hypertext system
to exploit this facility. Web-based knowledge-oriented systems are
currently either ontology servers
(e.g. Loom Ontosaurus [14])
or information-retrieval/brokering tools (e.g.
Ontobroker [15]).
For a long-term project, we are also studying how the Sisyphus-I problem-solving knowledge could be directly represented by a set of CGs [16] which would be used by a constraint satisfaction problem solver. Thus, these CGs would replace the script. The ontology and data set presented here would not have to be changed.
1. http://www.webkb.org/
2. http://www.webkb.org/kb/webkb1/sisyphus1.html
3. http://ksi.cpsc.ucalgary.ca/KAW/Sisyphus/Sisyphus1/
4. http://ksi.cpsc.ucalgary.ca/KAW/Sisyphus/Sis1/
5. http://www.w3.org/CGI/
6. ftp://ftp.inrialpes.fr/pub/opera/publications/ECHT92.ps.gz
7. http://www.isi.edu/isd/LOOM/LOOM-HOME.html
8. http://web.archive.org/web/*/http://goanna.cs.rmit.edu.au/~ged/publications.html
9. http://www.webkb.org/doc/languages.html
10. http://www.webkb.org/kb/webkb1/sisyphus1RecursiveScript.html
11. http://www.springerlink.com/link.asp?id=771p285705461q5k
12. http://www.w3.org/Library/
13. http://web.archive.org/web/*/http://developer.netscape.com/docs/manuals/communicator/jsref/index.htm
14. http://www.isi.edu/isd/ontosaurus.html
15. http://ontobroker.semanticweb.org/
16. http://www.webkb.org/kb/webkb1/sisyphus1Rules.html