We describe a knowledge base server named WebKB-2 that permits Web users to add knowledge in a shared knowledge base. The respect of certain lexical, structural, logical and ontological conventions is advocated to permit the comparison of knowledge representations proposed by the various users and therefore the inter-connection, retrieval and reuse of these representations. Lexical facilities, editing protocols and filtering mechanisms permit users to complement each other knowledge, focus on knowledge of a certain kind or created by certain users or kinds of users, and use the names they want for categories in their representations. The knowledge base has been initialized with the natural language ontology WordNet and a top-level ontology for simplifying, guiding and controlling the user in their representation work. Though WebKB-2 may be used for representing the content of documents and therefore index them, the entering and retrieval of knowledge per se is a thiner-grained approach that permits much more precision and completeness than document indexing and retrieval. Therefore, we think the features of WebKB-2 are best exploited as a support for the cooperative buiding and search of large and complex Yellow-Pages-like catalogues. WebKB-2 is usable at www.webkb.org.
Keywords: Knowledge Representation/Retrieval, Ontology Server, Cooperation, Conventions, RDF.
Current Web search engines can retrieve documents that include some given
keywords but cannot extract and therefore retrieve and inter-link precise
information (or knowledge) from them. Knowledge retrieval and interlinking
is (re)done by each person using its own memory.
For instance, each person trying to find a good database system for a project
has to search and then read the documentation of many sytems, find some
comparative criteria and try to classify each system against these criteria.
With some luck, some of these searchers will encounter up-to-date comparisons
of still available systems against criteria relevant to their project, and
feedback from users of some of these systems. Each search for a good system
(including the experimentations) is likely to be long, have sub-optimal
results, and remain unknown to (other) database system seekers or providers.
This example is typical of many other searchs: car, insurance company,
employer/employee, software, hardware, methodology, service, etc.
To solve some of these problems, the current trend is to keep
the document-based/distributed approach of the Web and permit Web users to
create documents containing knowledge representations. The representation
model proposed by the W3C is the
Resource Description Framework [RDF] and
its textual syntax RDF/XML.
Unfortunately, this model and this syntax are
too simple and cumbersome to permit Web users to
write and reuse knowledge representations other than very simple ones.
In [Martin & Eklund, 2000], we proposed lexical and structural conventions
for extending RDF expressivity and reducing the number of ways semantic
content can be expressed (to improve the possibilities of comparing
representations and hence their retrieval and interlinking).
In [Martin, 2000], we proposed high-level
ontological conventions, higher-level notations, and a Web-based inference
engine (WebKB-1) [Martin & Eklund, 2000b] to expoit these notations.
However, even if the conventions we propose became standards and were followed,
in this distributed approach, there would be a large number of small competing
and loosely inter-linked ontologies (schemas) and hence automatic
comparison of representations would remain limited or continue to use
lexical matching and be inexact.
General and domain-specific large ontologies currently exist (e.g. CYC, WordNet, Snomed) and it is likely that they will be reusable via ontology servers since it would be inefficient to use these ontologies simply stored as RDF schemas within documents. Ontology servers would be reused by RDF users since it would spare them effort and improve the accessibility of their work. As detailed later in this article, we have designed an ontology server for WordNet complemented with a top-level ontology for guiding knowledge modelling. It can be reused from RDF schemas, though this approach would also be relatively inefficient to use by an RDF engine not based on the same machine as the ontology server (because of numerous network access that would have to be done). The next logical step toward centralization, and hence better automatic and manual knowledge comparison, inter-linking, cross-checking and cooperation between knowledge providers, is to propose knowledge-base servers where Web-users may publish their knowledge (or knowledge requests) using high-level interfaces and complement the knowledge of other users. For efficiency and commercial reasons, we would not expect all Web-users to use the same knowledge base server but a few general knowledge servers (for example managed by portal companies such as Altavista, Yahoo or Netscape) and more specialized knowledge servers. By mirroring one another, they would share a similar general WordNet-like or CYC-like ontology and competing specialized knowledge servers would also share a similar content. It should be noted that the processes of mirroring and answering queries involving several knowledge bases is by itself permitted by the similarity or interconnection of the various used ontologies (we detailed these processes in [Martin and Eklund, 1998]). Thus, it would not really matter where a Web user publishes his/her information first and this centralized approach would keep the advantages of the current distributed approach.
Whether future knowledge base servers really have equivalent ontologies or not, knowledge base servers permitting their users to find and write knowledge more easily and complement other users' knowledge is an interesting complement to the current document-based approach, if only for permitting cooperatively-built yellow-pages-like catalogues. In this article, we detail some structural, lexical, syntactic, logical, and ontological requirements we think necessary for such a knowledge base server. We show how our knowledge-base server (WebKB-2) satisfies them, the protocols we advocate for controlling the cooperative edition of the knowledge base by multiple users and finally the search and filtering mechanisms we implemented to permit the access to the knowledge. Finally, we compare our approach with other ones.
We believe the first requirement for a general knowledge base server is to
support a knowledge representation language
(i) expressive enough to permit and encourage the user to be exact in
his/her representations, and
(ii) limiting the number of different (and not automatically comparable)
ways to express the same information.
If the language is not expressive enough the users will either enter wrong
information, develop various incomparable ways to represent it, or simply
not use the server. Any of these cases will hinder knowledge comparison,
cross-checking, inter-linking and reuse.
Furthermore, the various ways the knowledge will be reused by applications
using the servers cannot be foreseen and therefore precision
should not be arbitrary limited.
This does not mean that the server should have inference capabilities that
exploit all the subtleties of the language. Implementing such an inference
engine would actually often involve application-dependant choices. Instead,
the server should perform minimal consistency checks and help to filter
knowledge relevant to answer a query -- or in other words, knowledge relevant
for an application -- and optionally translate this knowledge into standard
notations.
WebKB proposes various notations to its users, mainly Conceptual Graphs [CG] [Sowa, 1984], Formalized English (FE) and Frame-CGs (FCG). CG is a logic-based semantic network model similar in structure to RDF and supposed to be as expressive as the Knowledge Interchange Format [KIF] (though functions and constraints may be difficult to express, it can be used to represent first-order logic and contexts). Like many researchers before us, we originally chose CG because it has relatively intuitive graphical and textual notations and therefore would be easier to understand and use by knowledge engineers and eventually Web users. However, we found that various forms of quantification common in natural languages (e.g. "all", "most", "at least", "76%", "between 5 and 6", "dozens") are difficult to represent or there are no unique/standard ways to represent them. We therefore extended the CG model by adding such quantifiers (and a few other things) and derived FCG and FE from the CG textual notation to improve its readability and ease of use. Below is a simple example. More details will be given in section 4.
English: In 1999, 75% of Americans own a car.
FE: `75% of Americans are owner of a car' time 1999.
FCG: [[75% of Americans, owner of: a car], time: 1999]
CG: [situation: [American: {*}@75%]<-(owner)<-[car] ]->(time)->[date: 1999]
//note: they do not own the same car (the collection quantifiers are by default
// interpreted distributively and, at least in FE and FCG, the order of
// the concepts permits to determine the scope of the quantifiers);
// the 's' at the end of "Americans" is automatically removed.The CG model is composed of nodes (or concepts) connected by
relations. Each node includes (refers to)
(i) a category (formal term) representing an individual object
or a type of object,
(ii) a quantifier (existential quantifier only in
the basic/standard CG theory),
and optionally,
(iii) an embedded node (in that case, the embedding node refers to
a situation or a description of a situation).
Each relation refers to a relation type and is existentially quantified.
Categories are structured by subtype or instance
links. Like RDF "properties", relations are first-class objects
(i.e. they are not local to an object as in most object-oriented languages)
that can be connected to any concept providing that the signature of the
relation is respected. Though in CG, relations are not restricted to be
binary, we have not kept this feature in FE and FCG because its use leads to
graphs that are not only less precise than when concepts and basic
binary relations are used but also incomparable with them [Martin, 2000]
(unlike concepts, relations cannot have quantifiers nor relations
connected to them, and cannot be compared to other concepts).
Graph models permit simple and flexible searches of knowledge via graph
matching procedures. A common procedure is the search for the specializations
of a query graph: the specializing graphs must contain nodes and relations
with categories subtype or instance of those specified in the query graph, and the
connections between these nodes and relations must be identical to those
they specialize in the query graph (the specializing graph may have
other nodes and relations not in the query graph). If both the
specializing graph and the query graph are simple existential graphs
(no collection, no contexts, ..., only existentially quantified nodes and
relations), then the specializing graph logically implies the query graph
[Sowa, 1984] (e.g.
Since the knowledge base server is meant to be used and edited by
multiple users, we think a second important requirement is that to each category,
link between categories, concept and relation is associated a unique identifier of
its creator. Furthermore, since words in natural languages often have more
than one meaning, both words and categories should be stored and to each
category associated
(i) a key name that uniquely identifies it within the categories with same
creator,
(ii) a list of links to words that can be used to name the category
(to each of those links is associated an identifier of its creator
and/or the community/language for which this association is true).
Conversely, each word is associated to the categories that
represent its various meanings. Finally, each category creator or group of
creators should be represented by a category in the ontology. We initialized the current knowledge base of WebKB-2 with the
content of the lexical database
WordNet 1.7 [WN]:
108,000 nouns and 74,500 categories refered by nouns
(in accordance to the lexical conventions introduced in the next section,
we ignored information related to verbs, adverbs and adjectives).
Click here for details on how WordNet
was semantically and lexically corrected and completed to be used
in a KB, and merged into a top-level ontology of 100 concept
types (complemented by 140 basic relation types).
Various kinds of links connect WordNet categories: Although the semantics of In WebKB's interfaces or text input/output files, a category may be denoted
via an identifier that is either a url, an e-mail address or the
concatenation of the creator identifier and the key name,
e.g. Words (i.e. category names) are simply entered as such, e.g. In the knowledge base server we are describing, the ontology
is large and new categories can be added at any time. This being the case, the
ontology cannot be stored directly within the schema of an object-oriented
database (schemas of databases are small and defined at compilation time,
they cannot be updated
interactively). Theoretically, we could have implemented our server using a
relational database with a few tables such as Some naming conventions have been adopted in
[RDF] and the
Meta Content Framework
Using XML [MCF/XML]: category identifiers should follow the
"InterCap style" and categories which are not relation types ("properties") should
have their first letter capitalized.
However, this is not a good convention because
(i) the correct spelling of the words used in the identifiers cannot always
be recovered (e.g. for generating English or structured English);
(ii) it is not very readable,
(iii) in RDF, the correct spelling has to be specified via Hence, at least in WebKB, we recommend the use of the undescore character
to separate two words within an a name composed of several words and to use
capital letters only when they are are part of the usual way to write the words.
Thus, the capital letter information is saved, searches are eased, knowledge
representations are more readable and they can be automatically transformed to
suit other naming conventions.
Generally a sentence can be rephrased to avoid the use of adjectives and
verbs (with the exception of ``to be'' and ``to have'').
For instance, the sentence "John loves speed and red cars" can be
represented into the FE statement: Concept types denoted by adjectives can rarely be organized by
generalization relations but may be decomposed into concept types
denoted by nouns.
To help avoid adjectives, FE and FCG have qualifier keywords ("good", "bad",
"important", "small", "big", "great" and "certain") that can be used in
addition to quantifiers. Here is, for example, a representation of the sentence
"an healthy bird is on a big tree": Concept types denoted by verbs can be organized by generalization relations
(though the organization of the top-level types is difficult) but cannot be
inserted into the hierarchy of concept types denoted by nouns (and
therefore cannot be compared with them) unless verb nominal forms are used.
These nominal forms, e.g. Thus, the convention of using nouns, compound nouns or verb nominal forms
whenever possible within representations not only makes them more explicit,
it also efficiently reduces the lexical and structural ways they may be
expressed. It therefore increases the possibilities of matching them.
Most identifiers in current ontologies are nouns (e.g. the
Dublin Core or the
Upper Cyc Ontology),
even in relation type ontologies such as the
Generalized Upper Model relation hierarchy.
Avoiding adverbs for relation type names is sometimes difficult, e.g. for
spatial/temporal relations. However, this does not create problems in
organizing relation types by generalization relations. What should be avoided
is the introduction of relation type names beginning by "has" or "is",
ending by "of", or such as Most identifiers in ontologies are singular nouns.
Category identifiers must be in the singular in the Meta Content Framework
Using XML. Such identifiers can be quantified in various ways to obtain sets
but category that have an identifier in the plural form denote sets and are
difficult to (re-)use in statements and compare with other categories.
If you belong to the RDF community, you might prefer this (older)
RDF-oriented version of these lexical, structural and ontologigal
requirements.
A general multi-user knowledge base server must
be able to parse expressive knowledge representation notations and store
their content. The user should be able, and encouraged, to represent knowledge
precisely, since the more precise the representations, the less chance they
conflict with one another, and the more they can be cross-checked, and
exploited to answer queries adequately. Assuming the graph representing "birds fly" has been automatically
or manually given the identifier Contexts are delimited by square brackets in FCG and quotes in FE.
At a same context level, graph structuration is done via parenthesis in FCG
and the use of commas or keywords "and" in FE.
Lambda-expressions are delimited by parenthesis in FCG, square brackets in FE.
In FE, the keywords "that", "with", "has", "have", "is", "be" are optional
syntactic sugar.
The modality of physical possibility is represented via the keyword "can" in
FE and "#:" in FCG. The modality of event/logic possibility is represented
via the keyword "may" in FE and "<=" in FCG.
Apart from these distinctions, both notations share the same features:
quantifier keywords (e.g. "a" and "the" are existential quantifiers,
"several" and "at least" are collection quantifiers),
qualifier keywords (e.g. "good", "bad", "important", "small"),
the keyword "of" to reverse the direction of a relation,
automatic typing of contexts according to the signature relations connected to
them, normalization and and handling of undeclared categories.
The EBNF, Yacc and Lex grammars of FE and FCG are available at
http://www.webkb.org/doc/languages/. Although the above correction was semantically necessary, it does not
support many inferences. Valuable complementary information would come from
the specialization of the type In WebKB-2, links between categories may be directly entered via the interface,
a special notation for links, or via graphs. For example,
"Philippe Martin is a man" may be entered as
[Tom, owner of: (a car, color: the white)]
specializes and implies
[a person, owner of: a vehicle]
(since a car is a vehicle).
Searches for specializations permit such "by content" searches as opposed to
lexical searches. We discuss some extentions and our implementation of
such searches in section 7.
Information on creators is necessary for handling updates by multiple
users and permitting each user to filter or focus on the knowledge
from certain users by refering to them with an identifier, one or several
type or supertypes, or even a graph description. The alternative choice
of storing knowledge from each creator in a different module would not
permit as much flexibility in the management and filtering of knowledge from
multiple creators (or it would be harder to implement).
Links between categories and words are necessary to permit the use
of words instead of categories within graphs. Such a feature spares the users
the tedious work of looking for the identifiers of each category in their
graphs (statements or queries). If the word used in a concept
refers to only one category or if the other categories can be eliminated given the
signature of the relations connected to the concept, the category that is (most
probably) relevant can be found. Otherwise, the list of candidate categories
can be proposed for the user to select. For a query graph, there is no harm
in making an automatic choice and let the user refine the query if a wrong
category has been selected.
subtype,
exclusion, similar, member,
part, substance,
plus their reverse links.
subtype, instance and
exclusion links are clear, the semantic of other links are not.
For instance, does a part link from the category
airplane to the category wing mean that
"any airplane has for part at least 1 wing" or
"all airplanes have for part the same wing", "any wing is part of a plane",
"a wing is part of any plane", etc.
We assume the first interpretation is correct for all kinds of direct links
except subtype, instance and exclusion
(i.e. part, substance, etc.) and therefore opposite
for their reverse links (i.e. part of, substance of,
etc.).
wn#domestic_dog, wn#time,
wn#time.instant, pm#IR_system.
(Category identifiers with same key names but different creators refer to
different categories and therefore, hopefully, represent different objects).
The names of a category may also be shown, separated by "__", e.g.
wn#domestic_dog__dog__domestic_dog__Canis_familiaris and
pm#IR_system__information_retrieval_system (if the first name is
equal to the key name, it is not repeated). WordNet categories may also be
displayed/entered without their creator identifier (i.e. without the "wn"
prefix), e.g. #time.
More exactly, this is the case except
within graphs when a list of default creators has been specified (e.g.
with the command "default creators: pm wn;" in input files). Thus,
for instance, if pm and wn are the default
creators, [a #car] is accepted if either pm#car
or wn#car have been declared. The order of the creators in
the list is important (the first candidate category is preferred).
time
and domestic_dog.
Category names, instead of category identifiers, are accepted within graphs
only if the option has been selected (command "use names;" in input files).
Signatures are used for eliminating candidate categories. If there is more
than 1 candidate, the parsing stops or issues a warning
depending on an internal ambiguity acceptation level (for our main purpose,
ambiguities should not be allowed but an application of WebKB-2 that requires
an automated agent to be used as a knowledge provider will
probably accept ambiguities). If ambiguities are accepted and
a list of default creators specified, WebKB-2 exploits it to
select the best candidate category.
Apart from signatures, type constraints explicitly associated to categories within
a graph may be used to guess categories. For instance, in the graph
[a transformation \\pm#process], "transformation" is constrained
to refer to a specialization of the type pm#process. This permits
WebKB-2 to eliminate the two other senses proposed by WordNet: the mathematical
function and the transmutation. Top-level types such as pm#process
are proposed in WebKB-2 menus to help construct graphs.
For maximal readability, we will often use names instead of category identifiers
in the example graphs of this article.
User,
Term (or Category), TermName (or
CategoryName), Node and Relation.
To each category, we would have had to associate not just its direct
subtypes/supertypes (and the creators of these links), but also all
indirect supertypes to permit efficient accesses to the specializations of
a query graph. However, we found a free-to-use object-oriented main-memory
database system called
FastDB [FastDB]
with a high-level C++ API and interesting facilities such as the automatic
handling of reverse links, concurrent access to the data, log-less
transactions and zero time recovery.
Furthermore, in case the database is bigger than 4Gb (on a 32 bit system),
a disk-based version called
GigaBASE can be
used with the same API. We decided to use this system and our current
database (mostly containing the WordNet ontology) is 67 Mb (or less).
We considered the use of the
Parka-DB
system [Parka-DB] which is designed to be a scalable knowledge representation
system but could not find enough information
to determine if we could extend it to support our complex data structures
(cf. Appendix) and knowledge management procedures. In Parka-DB the ontology
is also entirely loaded in memory but the graphs remain on disk.
3. Lexical requirements
3.1. No intercap style for identifiers
xml:label
relations, which is cumbersome and rarely done;
(iv) it is more important to readily distinguish between types and individuals
(these last ones cannot be specialized) than between relation types and
concept types/individuals (furthermore, to avoid redundancies, ease the
production of knowledge representations and guide the users to write more
"normalized" representations, it is important to permit the use of certain
concept types within relation nodes; in WebKB-2, these are the 13100+ concept types
subtype of pm#thing_that_can_be_seen_as_a_relation,
most of them coming from WordNet; however, since such a type (say t)
has no associated signature, when it is used in a relation, only the type of the
destination node can be checked to be a subtype of t, no checking can
be done on the type of the source node).
3.2. Singular nouns for identifiers
John is experiencer of a love with object the speed,
and experiencer of a love with object most [car that has for color the red].
This statement is a specialization of the query graph
[a person, experiencer of: 2 love].
[a bird, experiencer of: a good health, on: (a tree, attribute: a big size)].
Driving, also recall the
need to represent the time-frame or frequency of the referred processes.
For similar reasons, value restrictors should also be represented
via noun phrases, e.g. ImportantWeightForAMouse and
ImportantWeightForAnElephant, rather than via adjectives
such as Important.
isDefinedBy and seeAlso.
Better relation type names are definition and
additionalInformation.
These names are consistent with the usual reading conventions
(e.g. in RDF
and CG [Sowa, 1994] ) of graph triplets
{concept source, relation, concept destination}:
``<concept source> HAS FOR <relation> <concept destination>'' or
``<concept source> IS <relation> <concept destination>'' or
``<concept destination> IS THE <relation> OF <concept destination>''.
4. Logical and syntactic requirements
For instance, a user should not simply represent that "birds fly"
(in FE: "any bird is agent of a flight") since this is false.
If this happens, other users should be able and encouraged to "correct"
the information. In WebKB-2, any user can do this by connecting the "faulty"
graph to a more precise version using a relation of type
pm#corrective_restriction (then, depending on display options,
the first version may or may not be filtered by WebKB-2 when answering
queries). Similarly, if a user thinks a
statement from another user can be generalized, the relation of
type pm#corrective_generalization can be used.
pm#graph289, below is an example
of correction by the user spamOnly@phmartin.info stating instead that
"a study made by Dr Foo found that in 1999, 93% of healthy birds could fly".
This example shows the importance of contextualizing information at least
with authors, times or geographic areas.
It is also intended to illustrate the possibilities of FE of FCG.
An explanation follows. Names are used and the default creators are pm and wn.
If the graph is entered via WebKB-2's interface, the graph creator is
automatically stored (with the creation date).
FE: `graph289 has for corrective_restriction
```93% of [bird experiencer of a good health] can be agent of a flying'
time 1999' with source a study that has for author Foo@bird.org'
' with creator spamOnly@phmartin.info.
FCG: [[graph289, corrective_restriction:
[[[93% of (bird, experiencer of: a good health), agent of #: a flying],
time: 1999], source: (a study, author: Foo@bird.org)]
], creator: spamOnly@phmartin.info]
The FastDB data structure we use for storing information about a concept is
given in Appendix.
wn#bird with two exclusive types
such as pm#bird_that_can_fly_when_adult_and_healthy
and pm#bird_that_cannot_fly_when_adult_and_healthy,
and the use subtype links to connect them to various types
for birds. WebKB-2 can exploit the exclusion links to make
semantic checks. Though, it cannot exploit more complex definitions such as
[any pm#bird_that_can_fly, pm#agent of #: a wn#flying],
they can be useful for applications using more powerful inference engines.
wn#adult_male: spamOnly@phmartin.info or
spamOnly@phmartin.info nbsp;^ wn#adult_male or
[spamOnly@phmartin.info \\wn#adult_male].
(If a category is given, "\\" permits the declaration of a new type for it; if a
name is given, "\\" permits to specify a type for the intended category).
Thus, links may be contextualized, as in
[[Joe, member of: Communist_Party], time: 1999] and
[[Joe \\pm#taxi_driver], from_time: 1/2/1999, to_time: 31/1/2000].
5. Ontological requirements and conventions
To improve knowledge retrieval, checking and reuse, we advise WebKB-2 users
to use precise categories and, when they enter new categories, relate them
to as many other types as possible, using links
(subtype, exclusion, part, etc.), relation signatures, and
definitions (graphs). Ideally, this work should ensure that no two categories
represent the same object or kind of object. The pre-existence of WordNet
categories constitutes a guide since various meanings are proposed for
most English words and each of these meanings is precised (and to some extent,
its use checked) via our top-level ontology. In the same line of reasoning,
if users do link their categories to relevant other categories, the knowledge
base will grow more and more precise and hence reusable.
Instance links should not be
over-used.
tap#product_type which has no other supertype than
rdfs#class. Even if it had, the use of a first-order type such as
#product permits much more comparison with (or connection or
inheritance of constraints from) other types, hence more retrieval and checking
possibilities.daml#transitive_property in
DAML+OIL ontology (DAML)
are justified (transitivity is a class property: the subtypes
of the class do not necessarily inherit this property).
However, when possible, subtyping a first-order type such as
pm#transitive_relation seems preferable.
(These last two types are proposed in the WebKB-2 ontology).
pm#physical_entity and wn#time_period. For example,
[pm#C_plus_plus, pm#description_instrument of: pm#WebKB-2]
is accepted if no version of WebKB-2 has been defined
as subtype or instance of pm#WebKB-2. Otherwise, the graph is
rejected and the subtypes/instances listed to guide the reformulation of
the graph.
We pointed out in Section 2 that relations should be kept basic and binary (e.g. they should not represent actions) to permit graphs to be explicit and comparable (since relations cannot have quantifiers nor relations connected to them, and cannot be compared to other concepts; see [Martin, 2000] for more details). This is the case with the 140 relation types in our top-level ontology. The signatures of these relations use the top-level concept types we used to structure and complement the top-level of WordNet. Thus, these relations guide the user in his/her knowledge modelling, permit to automatically check the use of WordNet categories, guess categories when names are given, and compare graphs. It is therefore important that they are reused. Given our experience of representing randomly chosen English sentences from books using this set of relation types, we do not anticipate that users will have to augment this relation type collection much for representing general knowledge (as opposed to technical/specialized knowledge). However, augmentation is not a problem as long as adequate specializations are made and the introduced types represent primitive relations.
Figure 2 shows the subtype
links between the uppermost concept types of our ontology. The FCGs below
list some important types and a few general-purpose relations typically
connected to concepts of these types. They can be viewed as a small
ontological model for how to represent knowledge.
This model was originally inspired from [Sowa, 1984] and more details can
be found in [Martin, 2000].
The categories in the FCGs below belong to the user "pm" and key names are used.
[any situation, //any situation (state or process)
place : a spatial_entity,// happens at a place (even an imaginary one)
time : a time_measure, // happens at a time
duration <= a time_measure, // may have a duration (events are processes
// considered instantaneous)
from_time : a time_measure, // has a beginning
until_time: a time_measure, // has an end
later_situation: a situation,// follows (at least) another situation
result <= a thing, // may have a result, ...
experiencer<= a conscious_agent, recipient <= an agent,
agent <= an entity, initiator <= a goal_directed_agent,
instrument <= an entity, object <= a thing
]
[any process, //(e.g. an action, a problem solving process, an event)
triggering_event<= an event, ending_event <= an event,
ending <= a state, ending of <= a state,
precondition <= a state, postcondition <= a state,
sub_process<= a process, purpose <= a situation,
method <= a description, to_place <= a spatial_entity,
via_place <= a spatial_entity, from_place <= a spatial_entity
]
[any description, //any graph ("proposition" in logic)
description_object of : a thing, // may be connected to what it describes
description_instrument: a description_medium, //(e.g. a symbol, a language)
description_container : a container_of_description, //(e.g. a file, a video)
author : 1 causal_entity, // has a unique author
believer <= a cognitive_agent, // may have one or several believers
modality <= a modality, // may be contextualized
logical_relation <=a description,//(e.g. "implication", "or")
rhetorical_relation <=a description //(e.g. "opposition")
argumentation_relation<=a description //(e.g. "proof", "contradiction")
]
[any spatial_entity, //(e.g. a point, an area, a volume, a physical_entity)
on_location <= a spatial_entity, above_location <= a spatial_entity,
in_location <= a spatial_entity, interior_location<= a spatial_entity,
out_location <= a spatial_entity, exterior_location<= a spatial_entity,
near_location<= a spatial_entity, before_location <= a spatial_entity
]
[any collection, //(e.g. a bag, a set, a sequence, a social_group)
size: a number, member <= a thing,
minimal_size <= a number, subcollection <= a collection
maximal_size <= a number, overlapping_collection <= a collection,
average <= a number, collection_complement <= a collection
]
Some of these relations, especially spatial relations, could be specialized to allow more precise modelling and further semantic checks. Some relations could be imported from CYC and Ontolingua top-level ontologies where, for instance, 2D and 3D spatial relations are distinguished. However, we do not expect the average user to spend his time searching for and using such precise relations. Besides, in some cases, the adequate specialized relations may be guessed from the nature of the connected objects, e.g. 2D vs. 3D spatial relations.
Another important ontological point is the
representation of attributes or characteristics and measures for them.
Though these two notions seem distinct and therefore should be represented
with two different types and their instances connected with a relation
"measure", it is often not obvious to distinguish them and
more intuitive to organize them via subtype links.
For example, "red" can be seen as both a color and a measure of color
equivalent to a certain interval in Hertz.
Similarly, an "important weight for a man"
can be seen as a weight and might be used as a generalization for weights
over 150 kg. WordNet uses subtype links for organizing attributes and
measures and we can expect many users to do so too. Finally, the use of
a relation "measure" is rather tedious. Therefore, we chose to introduce
the concept type pm#attribute_or_measure and the relation type
attribute (that can connect any object to an instance of
pm#attribute_or_measure) in our top-level ontology. Thus,
graphs like the following are permitted:
[some car, attribute: a weight] and
[some car, attribute: an important weight].
However, it is also necessary to accept more precise and intuitive graphs
such as [some car, weight: 1000 kg] and that
these are comparable to the previous kinds of graphs. To achieve this, firstly,
units of measure must be classified as subtypes of what they measure, e.g.
wn#kilogram__kg__kilo__key as subtype of
wn#weight (it is already a subtype of
wn#metric_weight_unit__weight_unit). This work has been completed
for all unit types in WordNet. Secondly, within graphs, we have allowed
the use of subtypes of pm#attribute_or_measure as if they
were relation types. We have also adapted the specialization algorithm to take
this facility into account. For similar reasons, we also allowed the
subtypes of wn#relation (e.g. wn#name and
wn#trade_name) to be used in graphs as if they were relation types.
Click here if you want more details on this issue.
A last ontological convention within WebKB-2 is to introduce and use
categories that minimize the size of the graphs. For example, it is better
to declare pm#Toyota_Corolla as a subtype of
wn#auto__car__auto__automobile
than as a subtype of wn#trade_name. In the first case,
ontology browsing is sufficient to discover various kinds of automobiles
and searching graphs about Toyota Corolla cars may be done with a query
graph of one concept. In the second case, searching Toyota Corolla cars
may only be done via query graphs such as
[some car, trade_name: Toyota_Corolla].
Both cases could be entered into the ontology and connected via graphs such as
[any Toyota_Corolla, trade_name: brand_Toyota_Corolla]
and [[any car *x, trade_name: brand_Toyota_Corolla], implication: [*x\\pm#Toyota_corolla]
but WebKB-2 is unable to exploit such graphs for making inferences
during searches for specializations, and it might be inefficient if it would.
Furthermore, such duplication is dangerous since some users would probably
specialize only one of the two cases.
We believe a scalable approach for cooperation between users of a knowledge
base server implies that two seemingly incompatible goals are reached:
(i) each user should be able to represent what s/he considers true, and correct
or complement other users' knowledge in a non-destructive manner,
use the categories and names s/he wants (providing that general lexical
conventions are respected and existing categories reused or specialized),
and should not have to discuss and find an agreement with other users
each time any inconsistency arises,
(ii) knowledge from different users should remain consistent and
tightly interconnected to permit comparison, search, cross-checking
and optimal unification (i.e. merge of what is common).
In previous sections, we have shown how these different points can be achieved and that they are not incompatible provided users connect their categories and graphs to other existing ones. Removal/modification/addition protocols are also required for semantic conflicts to be managed asynchronously and without person-to-person agreement. The following four paragraphs describe our approach.
1) A user may remove a category, link or graph only if s/he has created
it, unless this induces an inconsistency in the user's knowledge. If the category,
link or graph being removed is used by other users or is necessary for their
knowledge to remain consistent, it is actually not removed
but its creator is changed to one of the users relying on its existence.
In WebKB-2, inconsistency detection currently only exploits relation signatures
and exclusion links (exclusive types may not have common direct/indirect
subtypes or instances). However, we plan to exploit inconsistencies detected
by users and signaled with a relation of type pm#contradiction
between two graphs.
2) The owner of a category may modify a link connected to this category
so that the link uses an alternate (more adequate) category, unless that induces
an inconsistency. The owner of a relation type may modify the associated
signature, unless that induces an inconsistency (in that case, s/he must
modify the ontology or the graphs so that the inconsistencies disappear).
A user may not modify a graph that s/he has not created but
s/he can connect it to another graph via a relation of type
pm#overriding_specialization or pm#corrective_statement
(examples of subtypes: pm#corrective_generalization,
pm#corrective_specialization, pm#corrective_restriction
and pm#correction - this last relation type should only be used when
the ontology cannot be modified (or another relation type used) for correcting the
first graph).
Since graphs can be used for representing links, these 3 relation types
may be used by a user to ``correct'' links between categories.
Depending on display/filtering options, corrected graphs or links are
displayed/used for inference or not.
3) A user may add a graph or a link, even if s/he is not the owner of the connected categories, unless that induces an inconsistency or redundancy. For consistency and re-use purposes, WebKB-2 does not accept a graph that already has a specialization or a generalization in the KB; this feature is detailed in the next subsection. When this happens, the user must either refine her graph before trying to re-add it, modify the ontology or use one of the four "corrective" relations cited above.
4) In any of these cases, when the knowledge of a user is modified by another user, the first should be automatically notified of the change via e-mail or presented to him/her the next time s/he logs on to WebKB-2 (we have not yet implemented this part).
An alternative approach for category or link removal/modification/adding
is allowing the owner of a category to perform these operations on the categories or
links s/he has created even when that induces an inconsistency in other users'
knowledge. In this case, the inconsistency has to be repaired automatically.
Since the modification of a category or link corresponds to a change of
interpretation of a category (at least from the viewpoint of the above mentioned
other users), a way to repair the inconsistency is,
before doing the modification, to duplicate the categories
and links that should not be modified for inconsistencies to be avoided
(that is, basically, the modified category and some of its subtypes from the same
user). The duplicates are attributed to other users. We describe
algorithms for this process in [Martin, 1996]. Although this alternative
approach allows each user not to care about how his categories are used by other
users, it is far less optimal than manual corrections, reduces
cooperation between users and also the tight interlinking of their knowledge.
It is also complex to implement and cannot be extended to handle graph
modifications.
The WebKB-2 user may not add a graph g1 if it
contradicts, generalizes or specializes an existing graph g0,
without connecting g1 to g0 via a relation of type
pm#corrective_generalization, pm#corrective_restriction,
pm#correction or pm#overriding_specialization.
There is one exception: when g1 instantiates g0.
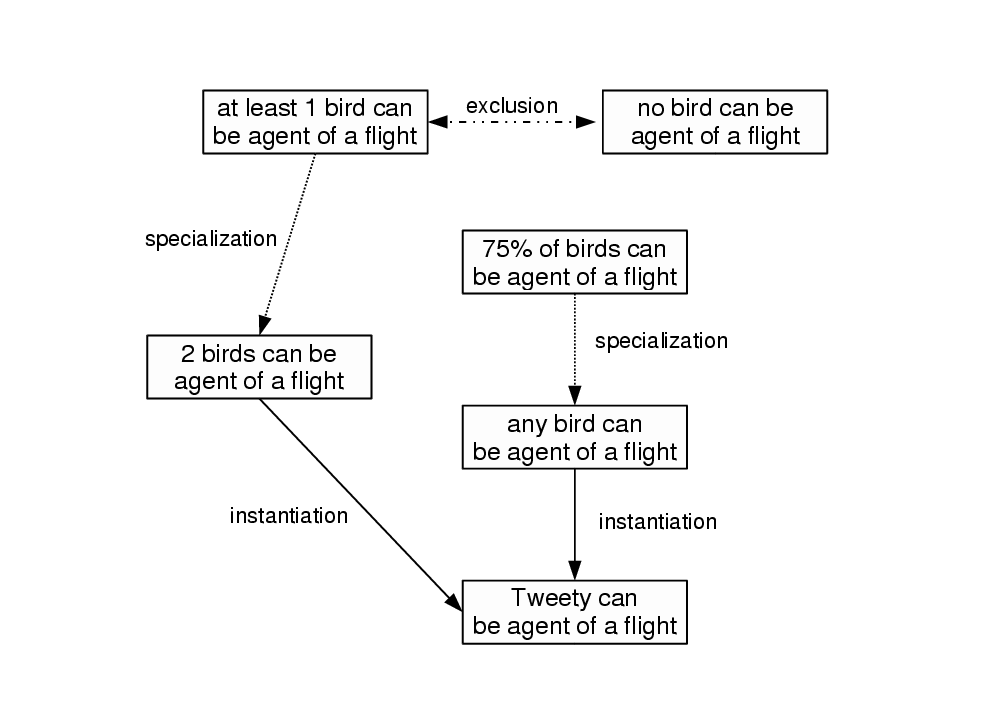
For example, consider the next figure where some statements
are represented in Formalized English (FE) and
exclusion/specialization/instantiation relationships between them are given.
A user is not allowed to enter "no bird can be agent of a flight" or
"2 birds can be agent of a flight" if the statement
"at least 1 bird can be agent of a flight" is already present in the KB.
Assuming its identifier is
pm#AtLeast1birdCanBeAgentOfFlight, the user should enter:
pm#AtLeast1birdCanBeAgentOfFlight has for corrective_restriction
`no bird can be agent of a flight' or:
pm#AtLeast1birdCanBeAgentOfFlight has for correction
`2 birds can be agent of a flight'.
However, a user may enter "Tweety can be agent of a flight" even if the
statements "2 birds can be agent of a flight" or
"any bird can be agent of a flight" already exist in the KB because
this is what we call an "instantiation": the new graph simply gives an
example or occurence of a more general statement (there is no potential conflict
between the authors' respective intentions).
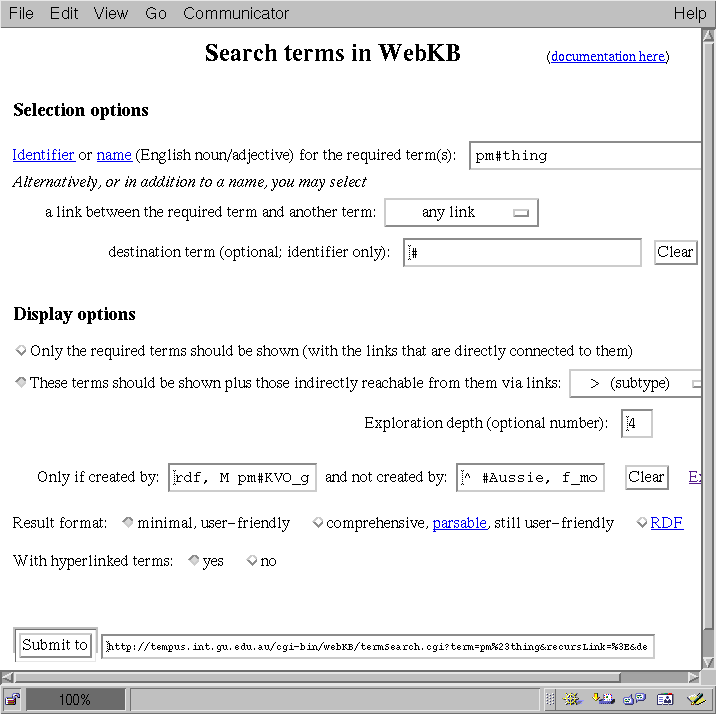
Figure 2 shows a WebKB-2 interface for searching categories or links
according to a category identifier or name and/or a link connected to the
category(ies) (there may be several categories if a name is provided) and an
optional destination. The kinds of links currently proposed are:
subtype, exclusion, similar, member, part, substance, location,
nounCategory, object, url and their reverses.
The links directly connected to the category(ies) are always presented.
Graphs using the category(ies) with a universal quantifier are also shown.
Display options permit to choose (i) if a particular link from the
category(ies)
should be recursively explored, (ii) what links or categories should be
filtered out according to their creators, (iii) what format or
language should be used for presenting the knowledge, (iv) if hyperlinks
should be associated to categories to permit navigation between them.
The text field next to the submit button shows the address of the called CGI
script and how the selected options are encoded in the parameters. This shows
users how they may direcly call the CGI script from programs. Each hyperlink
associated to a category actually contains the address of the CGI script with
the parameters necessary to display the category and all its supertypes.
When a name is provided and refer to several categories satisfying the additional
search constraints, blank lines separate the display of links related to each
category.
The parameters shown in Figure 2 specify a display of the category
pm#thing (the uppermost concept type in our ontology) and all
its direct or indirect subtypes created by the user rdf or
users that are members of the KVO group (M pm#KVO_group) apart
from f_modave and any Australian (^ #Aussie).
These filtering constraints resolve to the users rdf and
pm. Subtype links and categories that do not belong to these users
are explored but not shown. However, the indentation shows the depth level
of the categories according to the traversed links/categories even if they belong
to users other than rdf and pm, in order to
specify that intermediary categories and links have not been displayed.
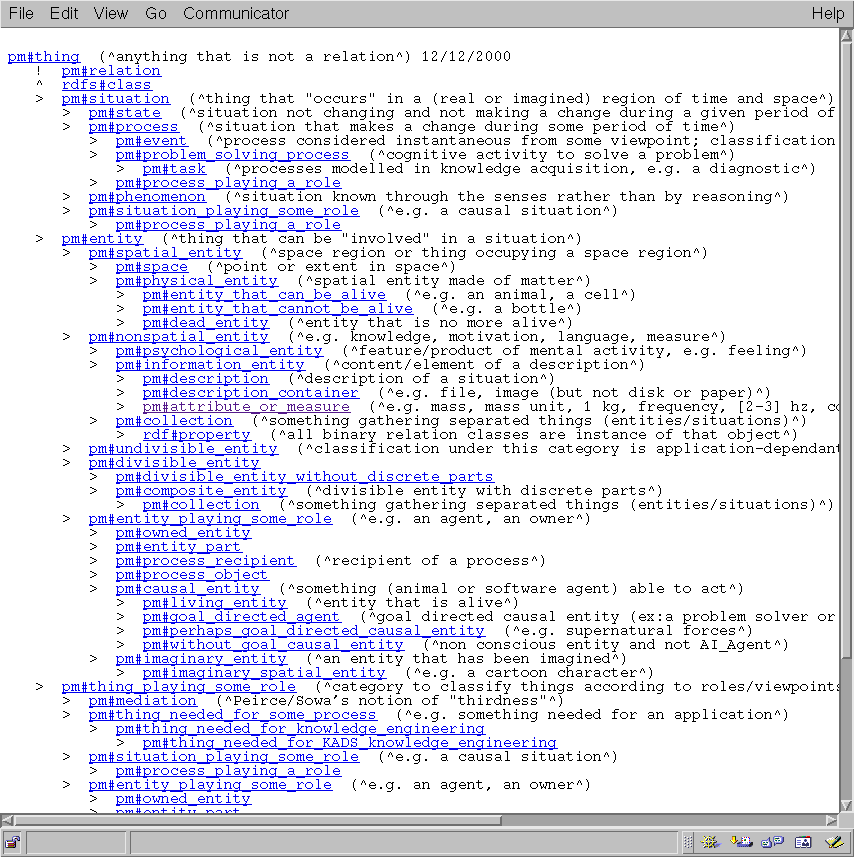
Figure 3 shows the result in the default format. The characters
'!', '^' and '>' respectively represent links of type exclusion,
instance of, subtype.
Figure 4 shows the result in RDF/XML. The characters '!', '^' and '>'
respectively represent links of type exclusion, instance of,
subtype.

Classic searches for specializations of a query graph [Sowa, 1984] permit searches "by the content" but need to be extended to permit more flexibility in the formulation of the query graph and provide a greater number of relevant answers.
First, let us assume the graphs [John, owner of: a car]
and [John, owner of: an appartment] are
in the knowledge base. A classic search for graphs specializing the query
graph [a man, owner of: a car, owner of: a lodging] would
not retrieve the previous graphs since only the union of these specialize
the query graph. When WebKB-2 looks for specializations, it also looks
for other graphs including coreferent categories: identical individuals,
identical types universally quantified or using the same coreference variable.
If they permit to answer the query graph, these different graphs are displayed
separately since joining them would often not produce a meaningful graph
(for example, their embedding graphs could not be joined). Here are,
for example, two other graphs that could be presented in answer to the
previous query:
[[[Tom \\IBM_employee, owner of: an apartment], time: 2000], author: Tom]
[[any IBM_employee, owner of: a car], author: IBM]
However, as noted earlier, WebKB-2 cannot perform type expansion (i.e. replace
a type by its definition within a graph) nor exploit logical rules.
Second, searches should also take into account knowledge
represented via links instead of graphs. For instance, let us assume the
categories representing the geographical areas "Gold Coast" and "Southport Coast"
are connected via a part link and the knowledge base includes
the following graph.
[spamOnly@phmartin.info,
agent of: (the renting,
object: (an apartment, part: 1 bedroom, location: Southport),
instrument: 140 Australian_dollars, period: a week,
beneficiary: Spirit_Of_Finance)]
WebKB-2 exploits the ontology to present this graph in answer to the query
graph
"[an apartment, location: (a district, part of: Gold_Coast)]".
Third, let us assume the graph [John, owner of: a lodging]
is in the knowledge base and a query graph is
[a man, owner of: an apartment]. The first
graph is not a specialization of the query graph since
wn#housing/2__lodging is a supertype of
wn#apartment__flat not the reverse. However, a user may want
such a graph to be provided. This is why Web-KB-2 provides two graph search
commands: "spec" to search specializations of the graph given in
parameter, and "?" to search graphs comparable to the one given in parameter.
With the second command, supertypes of categories in the query graph are also used.
The first graph would not answer the query
"? [a man, owner of: a bike]" since
wn#housing/2__lodging is not "comparable" with
wn#bicycle__bike__wheel (it is neither a subtype nor a supertype).
Fourth, structural flexibility should be permitted in query graph
specification. We believe the simplest way (both for the user and from
an implementation perspective) is to allow the specification of path sequences.
Common regular expression operators should be usable: '*' for "0, 1 or many
times", '+' for at "at least 1 time", '?' for "0 or 1 time".
For example, let us assume the following graph is in the knowledge base.
[spamOnly@phmartin.info, agent of: (a research, within_group: KVO_group)]
Users looking for a person conducting research at "Griffith University, Gold
Coast campus" are unlikely to find this graph via classic searches for
specialization only. However, given the category
pm#School_of_IT_at_Griffith_Uni_Gold_Coast_Campus is connected
via a part link to pm#KVO_group and
via a location link to
QLD#Gold_Coast_campus_of_Griffith_Uni, and given
pm#relation is the uppermost relation type,
it should be possible to find this graph with any of the following queries:
spec [a person, agent of: (a research, relation+:
Gold_Coast_campus_of_Griffith_Uni)]
spec [a research, (relation: a thing)+ location:
Gold_Coast_campus_of_Griffith_Uni)]
spec [a research, relation 3+ (part of: a group)3+ location:
Gold_Coast_campus_of_Griffith_Uni)]
"3+" means that a maximum of three relations of the specified type should be
traversed.
Search for path sequences will soon be included in WebKB-2.
For efficiency reasons, it is probable we will impose a limit on the
number of nodes and links to explore for searching specializations of path
sequences that use the relation type pm#relation.
Path sequences can only be used in query graphs formulated in FCG (see the
FCG grammar for more details).
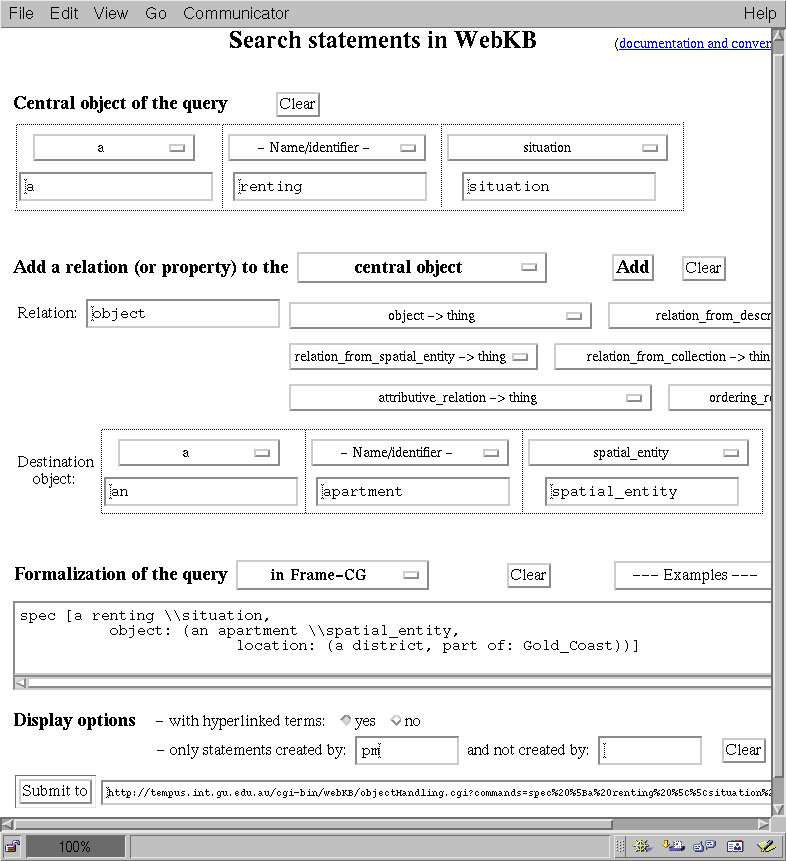
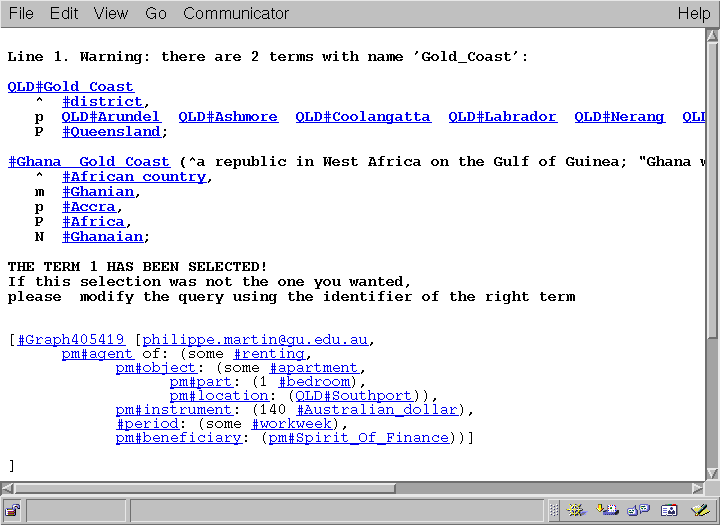
Figure 5 shows one of WebKB-2's interfaces for searching graphs. Menus may be used as an aid for building the query graph. Menus in Figure 5 show how a quantifier and a constraint type has been selected for the first object of the query graph and how the first relation has been added. Names, instead of category identifiers, have been used. Finally, "pm" has been specified as the creator of the graphs to retrieve. Figure 6 shows the result. It first indicates that 2 categories share the name "Gold_Coast" and that the first has been selected. Both are presented to permit the user to evaluate if the choice was correct. Then, a graph answering the query is presented. It is not presented using the text with which it has been entered because the option "with hyperlinked categories" has been selected in the query form.
Dan Brickley has implemented a Web server
[Brickey, 1999] providing
supertypes of a given category in WordNet. The RDF/XML notation is used to
present these supertypes. The server can therefore be referenced and used
as if it were a document containing an RDF schema about the given category.
However, this server use names as if they were category identifiers. The
presented links are therefore often incorrect. In Dan
Brickley words: "the current demo conflates 'word senses' with the words
associated with those senses".
Our server does not have this problem. A category may be accessed with a name
or with a category identifier,
and various links may be recursively explored. All direct links from the category
are also presented. If the selected language is not RDF/XML, all the graphs
which use a tem with an universal quantifier are also presented (WebKB-2 cannot
yet translate graphs in RDF/XML; however, it should be noted that the RDF
model does not explain how to represent universal quantifiers in graphs).
[Guarino & al., 1999] have developed an information retrieval system
called Ontoseek that exploits the WordNet lexical database and simple
existential conceptual graphs to store the content of yellow-pages
and product catalogs and then permit access in a flexible way.
They show that structured content representations coupled with linguistic
ontologies increase both the recall and precision of content-based retrieval.
More exactly, Ontoseek reuses
Sensus [SO] which mostly includes WordNet
and the Penman top-level ontology [GUM].
It is unclear from [Guarino & al., 1999] whether or not users can modify this
ontology but they apparently can enter simple existential conceptual graphs
via the interface or ask/tell communication protocols. Queries also use these
graphs and classic searches for specializations are performed.
Queries may use names instead of categories.
It is unclear if structural constraints in the ontology
are exploited to guess adequate categories and if there are actual relation types.
WordNet types which can heuristically be identified as
"role types" (or types for "relational nouns") may be used as relation types.
The graph is accepted unless the type of the relation destination can
heuristically be found exclusive with the role type.
The authors acknowledge that the lack of information about exclusion between
types in WordNet limits the checks that can be performed with this approach.
For example, assuming the names in the following graphs each refer to only
one category, the graph [person]->(child)->[student]
(i.e. [some person, child: a student]) would be accepted and
[person]->(child)->[plant] rejected, but
[eat]->(patient)->[house] and
[table]->(patient)->[house] would be accepted.
Thus, WebKB-2 has similarities in intent and approach with Ontoseek. However, we believe the notation proposed in Ontoseek is insufficient for a precise or adequate representation of yellow-pages-like catalogs with detailed descriptions of products or services. We consider the content of yellow-pages-like catalogs is as complex as any other technical or general document content. Precision or correctness in the representations may not be that important for Ontoseek since the knowledge is only intended to be used as an index for products in a catalog, not for reuse or unification with knowledge from many users, but WebKB-2 requires expressive notations, the handling of multiple users, and knowledge representation conventions. We have also shown in the previous section the insufficiency of classic searches for specializations.
WebKB-1 and WebKB-2 can be called "ontology servers", i.e. Web servers that permit users to build and publish ontologies. Most ontology servers also permit the construction of graphs without universal quantifiers and therefore could be called "knowledge base servers" but the possibility of modifying the ontology is a rarer feature. WebKB-1 and WebKB-2 are two opposite extremes in the handling of cooperation between users: while most other ontology servers (e.g. the Ontolingua ontology server [Ontolingua], Ontosaurus [Ontosaurus], Ikarus [Ikarus], Tadzebao and WebOnto [Tadzebao]) store the knowledge of users in independant modules/files on the server disk, WebKB-1 uses Web-accessible files stored by users on their own disks and WebKB-2 stores the knowledge of users in a single knowledge base on the server disk. Some ontology servers, e.g. the Ontolingua server or Ontosaurus permit any user or a group of users to edit the module but, apart from locking/session mechanisms, no particular support for asynchronous cooperation is generally provided (no record of creators for categories/links/graphs, no conventions or protocols, etc.). An exception we know of is the Co4 [Co4] system which has protocols modelled on submission procedures for academic journals, i.e. on peer-reviewing, resulting in a hierarchy of knowledge bases, the uppermost containing the most consensual pieces of knowledge while the lowermost ones are the knowledge bases of each user. This approach certainly leverages some problems of module-based approach but can it scale to large knowledge bases or a large number of users? The Ontoloom/Powerloom authors mainly rely on knowledge comparison procedures and the pre-existence on a large ontology to guide and check users in their extension of a unique knowledge base.
Modules are an easy way to delimit knowledge about a particular subject and handle competing formalizations, but since categories between modules are generally not inter-connected, automatic comparisons of knowledge representations from/re-using different modules is unlikely to succeed. For the same reason, even when general descriptions of the content of modules are made using graphs, the selection of adequate modules to reuse or search is a difficult task. From a knowledge retrieval point of view, the indexation of knowledge according to some knowledge domains or other characteristics is a coarse-grained approach. In WebKB-2, the selection problem does not exist: categories are tightly interlinked, and each link or relation in the knowledge base may be used as an index for retrieving a relevant piece of knowledge, thus permiting to take into account any combination of characteristics specified in a query not just combinations given by users in general indexations.
We have presented an approach permitting Web users to search and cooperatively build a single knowledge base, and engineered a system supporting this approach. This system is accessible at www.webkb.org. The approach permits and relies on the reuse and interconnections at a local level: categories are links to names, creators and other categories, concepts and graphs are interconnected via relations or the categories they reuse. In coarser-grained approaches, these connections are often not represented (and, we believe, more difficult to represent in a manageable way) and therefore cannot be automatically combined to permit knowledge comparison or more relevant and complete knowledge retrieval. We proposed structural, lexical, logical and ontological conventions to be followed by the users for their knowledge to be more comparable. These conventions do not limit what the users can express, merely how it is expressed. This is important for the usability of WebKB-2 and the reusability of the knowledge. Finally, we proposed protocols to permit asynchronous cooperation between the users since synchronous cooperation (computer-supported or not) cannot scale to numerous or independant users.
Entering information in WebKB-2 is clearly more difficult than entering sentences in a document, but information from documents cannot be interconnected to answer precise queries and is therefore lost for most people. We believe that entering information in WebKB-2 is easier than in most other systems thanks to the adapted notations, the initialisation of the knowledge base with WordNet and our top-level ontology, the possibility of using usual words instead of category identifiers. Some information will remain difficult to represent precisely, for example that an appartment is "for rent". However, we think that WebKB-2, or an extension of it with nicer interfaces, can be used by Yellow-Pages-like-services or community servers to permit people to advertize products and services or publish information. When such information can be expressed in RDF/XML, WebKB-2 will also use this language as an input/output notation.
This work is supported by a research grant from the Distributed Systems Technology Centre.

D. Brickley: WordNet in RDF/XML, Mail message, http://lists.w3.org/Archives/Public/www-rdf-interest/1999Dec/0057.html
N. Guarino, C. Masolo, and G. Vetere: Ontoseek: Content-based Access to the Web, IEEE Intelligent Systems, Vol. 14, No. 3, pp. 70-80, May/June 1999. http://www.computer.org/Intelligent/ex1999/x3070abs.htm
Ph. Martin, and P. Eklund: Conventions for Knowledge Representation via RDF, WebNet2000 (ACCE press, pp. 378-383), San Antonio, Texas, November, 2000. http://www.webkb.org/doc/papers/webnet00/
Ph. Martin: Conventions and Notations for Knowledge Representation and Retrieval, Proceedings of ICCS 2000, 8th International Conference on Conceptual Structures (Springer Verlag, LNAI 1867, pp. 41-54), Darmstadt, Germany, August 14-18, 2000. http://www.webkb.org/doc/papers/iccs00/iccs00.ps
Ph. Martin, and P. Eklund: Knowledge Indexation and Retrieval and the Word Wide Web, IEEE Intelligent Systems, special issue "Knowledge Management and Knowledge Distribution over the Internet", May/June 2000. http://www.webkb.org/doc/papers/ieee99/ieee99.ps
Ph. Martin, and P. Eklund: A Key for Enhanced Hypertext Functionality and Virtual Documents: Knowledge, Proceedings of the Workshop "Virtual Documents, Hypertext Functionality and the Web" at WWW8 (technical report UBLCS-99-10), May 11, 1999. http://www.webkb.org/doc/papers/www8/dynamicDoc.html
Ph. Martin: Exploitation de graphes conceptuels et de documents structurs et hypertextes pour l'acquisition de connaissances et la recherche d'informations, Ph.D thesis, University of Nice - Sophia Antipolis, France, 1996. http://www.webkb.org/doc/PhD.html
J.F. Sowa, Conceptual Structures: Information Processing in Mind and Machine. Addison-Wesley, 1984. See also: http://www.bestweb.net/~sowa/cg/