Keywords:
knowledge representation/normalisation/sharing/retrieval/learning/evaluation,
design principles for learning objects,
learning object reusability/interoperability/repositories
Table Of Contents
1. Introduction (p.1)
2. Background: Current Information Retrieval/Sharing Approaches Are Not Scalable (pp.2-4)
2.1. Approaches Based on the Indexation of Resources Are Not Scalable (p.2)
2.2. Approaches Based on Either Fully Formal or Mostly Informal Resources Are Not Scalable (p.4)
2.3. Approaches Based on Mostly Independently Created (Semi-)Formal Resources Are Not Scalable (p.5)
3. Main Focus: Approaches for Scalable Knowledge Sharing
(pp.5-8)
3.1. Supporting Knowledge Sharing Between KBs (p.5)
3.2. Supporting Collaborative Knowledge Editions Within a KB (p.6)
3.3. Supporting the Valuation and Filtering of Knowledge or Knowledge Sources (p.7)
3.4. Supporting Knowledge Entering and Normalization (p.7)
4. Future Trends: Bigger and Fewer Knowledge Repositories (p.9)
5. Conclusion (p.10)
6. References (p.10)
7. Key Terms and Their Definitions (p.11)
The smaller and less contextual the "learning objects (LOs) available for re-use" are, and the more precisely indexed or inter-connected via metadata they are, the more easily they can be semi-automatically retrieved and combined to create "LOs to teach with" that are adapted to particular course objectives or kinds of users, and thus create contextual LOs (Downes, 2001) (Hodgins, 2006). Although this general idea is well advocated in the LO community, its ultimate conclusion - the idea that we advocate - is hardly attempted or even written about: each "re-usable LO", which from now on is simply referred to as an "object", should either be one formal term (a category identifier) or an "un-decomposable statement" (typically, one semantic relation between two other objects, with some information about the context of this relation, such as its creator and temporal, spatial or modal constraints on its validity, all of which preferably being expressed in a formal way, that is, with a knowledge representation language). Furthermore, each object should be connected to all other semantically related objects by semantic relations. In other words, there should be no difference between data and metadata, and there should be only one virtual well-organized knowledge base (KB) that all object providers can complement by inserting their objects "at the right place", or more generally, in a "normalized way" that permits the KB to stay well organized and hence to be searched and updated in an efficient or scalable way. A virtual KB does not imply only one actual KB, it simply means that all potential redundancies and inconsistencies detected by people or inference engines should be removed. As explained in Section 3.1, this also does not imply that knowledge providers have to agree with each other.
Nowadays, there is no such virtual KB, and repositories for learning objects (LOs) are not even KBs, they are databases for informal documents containing many more than one un-decomposable statement. Furthermore, current LO related standards (e.g., AICC, SCORM, ISM, IEEE WG12) and projects (e.g., CANDLE, GEODE, MERLOT, VLORN) essentially focus on associating simple meta-data to whole documents or big parts of them (e.g., author, owner, terms of distribution, presentation format, and pedagogical attributes such as teaching or interaction style, grade level, mastery level and prerequisites). Such superficial indices do not support the answering of queries such as "What are the arguments and objections for the use of an XML-based format for the exchange of knowledge representations?", "What are all the tasks that should be done in software engineering according to the various existing 'traditional system development life cycle' models?" and "What are the characteristics of the various theories and implemented parsers related to Functional Dependency Grammar and how do these theories and parsers respectively compare to each other?". Answering such queries requires presenting and allowing the browsing of the KB as a semantic network: (i) for the first question, a network with argumentation, objection and specialization relations, (ii) for the second question, a subtask hierarchy of all the advised tasks, and (iii) for the third question, a network with specialization relations between the various objects or attributes related to the theories and parsers.
LOs have special purposes but no special content; hence, all the advanced information sharing or retrieval techniques can be directed applied to LOs. On the Web, this means using Semantic Web related techniques (Shadbolt et al., 2006). However, almost all of them are about supporting the manual/automatic indexation of whole formal/informal documents or merging the content of independently created formal documents. Although document-based techniques and synchronous collaboration techniques respectively permit to exploit legacy data and not-yet-stored information, their efficiency or scalability for organizing, sharing and searching increasingly large amounts of information is limited. Hence, these techniques should ideally only be used as a complement to the building of a global virtual KB, not as sole techniques for exploiting information. This is the theme of the next section. Then, we show how such a virtual KB - on the Web or within the semantic/learning grid of a community - can and ultimately will be collaboratively built and hence used as a shared medium for the tasks of researching, publishing, teaching, learning, evaluating or collaborating.
Definitions. In this article, a "formal term" is a symbol (character string, icon, sound, etc.) whose meaning (i.e., the referred concept/relation type/individual) has been made explicit, a "statement" is a small set of symbols connected by relations, an "informal statement" is a statement without formal terms (e.g., a sentence in English), a "formal statement" is a statement with only formal terms, a "semi-formal statement" is a statement with formal relations and may be formal terms for concepts or individuals, an "object" (or re-usable LO) is either a term or a statement, an "ontology" is a set of formal objects (e.g., a small flat list or a full KB), a "resource" is a stand-alone collection of several statements (e.g., an ontology, a database, a document, a section or a paragraph), and "metadata" is a set of one or several numerical values or other objects used for relating or indexing one or more statements, typically those of a resource. Some metadata related to some resource or created by some person(s) can also be considered as a resource. Section 7 defines knowledge sharing, normalization, comparison and retrieval.
The more statements a resource contains, and the more resources there are, the more these resources contain similar and/or complementary pieces of information, and hence the less the metadata for each resource can be useful: queries will return lists of resources that are partially redundant or complementary with each other and that need to be manually searched, compared or aggregated by each user. Furthermore, the more statements a resource contains, the more its metadata have to be information selective, and hence the less such metadata are representative of the contained pieces of information and the more the indexation methods and usefulness are task/user/domain dependent.
Finally, the more statements some resources contain, and the less formal the statements are (or the more "contextual" they are), the less any similarity measure between these resources can have any intuitive or semantic meaning, and the less it is possible to relate these resources meaningfully by rhetorical or argumentation relations such as "arguments", "proves" or "specializes". For example, the statement "some animal sits above some artefact" is a generalization (i.e., logical implication) of both "Tom (a cat) sits on a blue mat" and "any animal sits above some artefact" because all the objects and quantifiers of the first statement are identical or generalize those of the second and third statements (such relations can be automatically inferred if the statements are formal or semi-formal). However, such relations rarely hold between two collections of statements, and especially between any two documents. Statistical similarity measures between documents, ontologies or metadata, have no semantic meaning: they are experimentally designed to be of some help for some specific kinds of data, tasks or users. For example, Knowledge Zone (Lewen et al., 2006) allows its users to rate ontologies with numerical or free text values for criteria such as "usage", "coverage", "correctness" and "mappings to other ontologies", also allows its users to rate each other users' ratings, and uses all these ratings to retrieve and rank ontologies. This approach compounds several problems: (i) whole ontologies are rarely genuinely/intuitively comparable (given two randomly selected ontologies, it is very rare that one fully includes or specializes the other), (ii) giving numerical values for such criteria is rather meaningless, (iii) textual values for each of such criteria cannot be automatically organized into a semantic network, (iv) two sets of criteria are rarely comparable (one set rarely includes all the criteria of the other set and has higher values for all these criteria), and (v) similarity measures on criteria only permit to retrieve possibly "related" ontologies: the work of understanding, comparing or merging their statements still has to be (re-)done by each user.
To sum up, however sophisticated, techniques that index resources are inherently limited in their possibilities and usefulness for information seekers. Furthermore, since they do not provide re-use mechanisms, they force information providers to repeat or re-describe information elsewhere described and thus add to the volume of redundant data that information seekers have to sift through. Yet, techniques to index data or people form the bulk of LO retrieval/management techniques and Semantic Web related techniques, for example in the Semantic Learning Web (Stutt & Motta, 2004) and the Educational Semantic Web (Devedzic, 2004). Although the number and apparent variety of these techniques is huge, our definitions permit to categorize most of them as follow:
As noted in the introduction, current LO-related standards focus on associating simple meta-data to (big parts of) documents, and current LOs are almost never about one un-decomposable statement only. For example, a typical LO about Java is an "Introduction to Java" listing some features of Java and giving an example of code, instead of being a relation between Java and one of its features. According to the IEEE LTSC (2001), a LO should consist of 5 to 15 minutes of learning material. Each of such LOs cannot be a "truly re-usable LO" (object) but is a package of objects selected and ordered to satisfy a certain curriculum. Although such packages are useful for pedagogical purposes and ease the task of most course designers since they are ready-made packages, they are black-box packages, that is, their decomposition into objects from a shared well-organized KB has not be made explicit and hence they cannot be easily modified nor compared or efficiently retrieved: they can only be retrieved via keywords, not via arbitrary complex conceptual queries on the objects they contain or, from a browsing viewpoint or a conceptual querying efficiency viewpoint, they cannot be organized into a lattice (partial order) according to the objects they combine.
Some information repository projects use formal KBs, e.g., the Open GALEN project which created a KB of medical knowledge, the QED Project which aims to build a formal KB of all important, established mathematical knowledge, and the Halo project (Friedland et al., 2004) which has for very long term goal a system capable of teaching much of the world's scientific knowledge by preparing and answering test questions for students according to their knowledge and preferences. Such formal KBs permit to support problem solving but they are not meant to be directly read or browsed, and designing them is difficult even for teams of trained knowledge engineers, e.g., the six-month pilot phase of Project Halo was restricted to 70 pages of a chemistry book and had encouraging but far-from-ideal results. Hence, such fully formal KBs are not adequate for scalable information sharing or retrieval.
Informal documents (articles, emails, wikis, etc.), that is, documents mainly written using natural languages such as English, as opposed to knowledge representation languages (KRLs), do not permit objects to be explicitly referred and interconnected by semantic relations. This forces document authors to summarize what has been described elsewhere and make choices about which objects to describe and how: level of detail, presentation order, etc. This makes document writing a time consuming task. Furthermore, the lack of detail often makes difficult for people or softwares to understand the precise semantic relations between objects implicitly referred to within and across documents. This leads to interpretation or understanding problems, and limits the depth and speed of learning since retrieving or comparing precise information has to be done mostly manually. The automatic indexation of sentences within documents permits to retrieve sentences that may contain all or parts of some required information (this process is often called "question answering"; tools supporting it are evaluated by the TREC-9 workbenches) but the lack of formalization in the sentences often does not permit to extract and merge their underlying objects and relations.
Cognitive maps and concept maps (Novak, 2004) - or their ISO version, topic maps - have often been used for teaching purposes. However, they are overly permissive and hence do not guide the user into creating a principled, scalable and automatically exploitable semantic network. For example, they can use relations such as "of" and nodes such as "other substances" instead of semantic relations such as "agent" and "subtask", and concept names such as "non_essential_food_nutrient". Thus, concept maps are often more difficult to understand or retrieve, aggregate and exploit than regular informal sentences (from which, unlike deeper representations, they can currently be automatically generated); Sowa (2006) gives commented examples.
Similarly, the modelling of the preferences and knowledge of students or other people is often very poor, e.g., a keyword for each known LO (e.g., "Java") and a learning level for it (e.g., "advanced"). This is for example the case with the CoAKTinG project (Page et al., 2005) which aims to facilitate collaboration and data exchange during or after virtual meetings on a semantic grid, and the Grid-E-Card project (Gouardères et al. 2005) which manages a model of certification for each LO and each student on a grid to facilitate her learning and insertion within relevant communities. A more fine-grained approach in which all the statements for which a student has been successfully tested on are recorded is necessary for efficacy and scalability purposes.
We believe that the main reasons why more knowledge-oriented solutions
are not developed can be listed as follow:
1) most people, including many tool developers, have little or no knowledge about
semantically explicit structures,
2) many tool developers fear that people will be "scared away" by the looks of
such structures or by having to learn some notations,
3) precise and correct knowledge modelling is complex and time-consuming,
4) KB systems are not easy to develop, especially user-friendly ones supporting
collaboration between their users,
5) there currently exists a lot of informal legacy data but very little
well-organized explicit knowledge.
Point 2 was the reason given by many creators of
"knowledge-oriented" hypermedia systems or repositories to explain the limited
expressiveness of the formal features or notations proposed to the users.
This was for example the case for the creators of
SYNVIEW (Lowe, 1985), AAA (Schuler & Smith, 1992), ScholOnto (Buckingham-Shum et al., 1999)
and the Text Outline project (Sanger, 2006).
Shipman & Marshall (1999) note that the restrictions of knowledge-based hypermedia
tools often lead people not to use them or to use them in biased ways.
Although this fact appears to be
presented as an argument against knowledge-based tools, it is actually an argument against
the restrictions set to ease the tasks of tool developers (especially
for designing graphical interfaces) and supposedly to avoid confusing the users.
We agree with the conclusion of Shipman & Marshall (1999) that annotation tools
should provide users with generic and expressive structuring features
but also convenient default options, and the users should be allowed to describe
their knowledge at various levels of details, from totally informal to totally
formal so that they can invest time in knowledge representation incrementally,
collaboratively and only when they feel that the benefits out-weight the costs.
The above points 1 to 5 are valid but we believe that
effective or scalable knowledge sharing and retrieval cannot be achieved without a
global virtual KB, and
to a large extent, without this KB being collaboratively directly updated by the
information providers themselves. Although this requires the learning and use of
graphical or textual notations for representing information precisely,
we do not think this will be a problem in the long term: the need for programming
languages and workflow or database modelling notations is already
well accepted and more and more students learn them.
Since the need for small LOs has been recognized and since it is part of the roles
of teachers and researchers to (re-)present things in explicit and detailed ways,
a global virtual KB is likely to be updated by them first.
Their students would then complement it, thus providing their teachers a way to
evaluate their knowledge and analytic skills.
Like previous distributed knowledge sharing strategies, the W3C's strategy is minimal: the W3C only proposes a low-level KRL (RDF+OWL) and some optional rudimentary "best practices" (Swick et al., 2006), and envisages the Semantic Web to be composed of many small KBs (RDF documents), more or less independently developed and thus partially redundant, competing and very loosely interconnected since the knowledge provider is expected to select, import, merge and extend other people's KBs into her own (Rousset, 2004). This formal document relying approach has problems that are analogue to those we listed for informal documents: (i) finding relevant KBs, choosing between them and combining them is difficult and sub-optimal even for a knowledge engineer, let alone for softwares, (ii) a knowledge provider cannot simply add one object "at the right place" and is not helped nor guided by a large KB (and a system exploiting it) into providing precise and re-usable objects that complement the already stored objects, and (iii) as opposed to normalized insertions into a shared KB which directly or indirectly guide all other related insertions, creating new ontologies actually increases the amount of poorly interconnected information to search, compare and merge by people or software agents. Most of current Semantic Web related approaches focus on supporting the manual setting or automatic discovery of relations between formal terms from different ontologies. Euzenat et al. (2005) gave an evaluation of such tools and concludes that they are quite understandably very imperfect but can be sufficient for certain applications. Euzenat (2005) recognizes the need for the approach we advocate: (semi-)formal KBs letting both people and software agents directly exploit and save new knowledge or object alignments, that is, query, complement, annotate and evaluate the existing objects, guided by these large and well-organized KBs. Those ideas are further developed in the next section.
This section focuses on techniques to support the only approach that we deem efficient and scalable for knowledge sharing and retrieval on the internet or within large intranets: the collaborative creation of a global virtual well-organized (semi-)formal KB without redundancies nor implicit inconsistencies. This implies techniques supporting (i) knowledge replication between KBs, (ii) collaborative knowledge edition within a KB, (iii) the valuation and filtering of knowledge or knowledge sources, and (iv) knowledge normalization.
In a global virtual KB, it should not matter which (non-virtual) KB a user or agent chooses to query or update first. Hence, 1) object additions/updates made in one KB should be replicated into all the other KBs that have a scope which covers the new objects, and 2) a query for which the content of a KB will not yield a complete answer (with respect to the content of the virtual global KB) should be forwarded to the appropriate KBs. To achieve those points, in (Martin et al., 2006) we note that each KB server can periodically checks more general servers, competing servers and slightly more specialized servers, and (i) integrates all the objects generalizing the objects defined in the reference collection that defines the scope of this KB server (a list of objects and possibly some maximum depth for some relations from these objects; for a completely general server, this collection is reduced to the most general conceptual category imaginable, which is often named "Thing"), (ii) integrates all the objects (and direct relations from/to them) more specialized than those in the reference collection until it reaches a maximum specialization depth if one has been specified (if so, the URL of the object is stored instead of the object), and (iii) also stores the URLs of the direct specializations of the generalizations of the objects in the reference collection (this is needed for any object in the global virtual KB to be directly or indirectly referred to). This seems the simplest approach because (i) the approaches used in distributed databases would not work since KBs do not have any fixed conceptual schema (they are composed of large, explicit and dynamically modifiable conceptual schemas), and (ii) a fine-grained classification or ontology for all the objects is necessary since classifying servers according to fields or domains is far too coarse to index or retrieve knowledge from distributed servers, e.g., knowledge about "neurons" or "hands" are relevant to many domains. This approach would work with servers on the Web but also in a peer-to-peer network where each user has her own KB server: the main difference is that a peer-to-peer network will permit to implement systematic push/pull mechanisms instead of relying on KB servers to regularly check the KBs of other servers and integrate new additions. We have not found any other research aiming to solve the above specifications 1 or 2. The works dealing with "Ontology Evolution in Collaborative Environments", e.g., (Vrandecic et al., 2005) and (Noy et al., 2006), or (Rousset, 2004) in a peer-to-peer context, are solely about accepting/rejecting and integrating changes made in other KBs, not about making these KBs have an equivalent content for their shared sub-scopes.
Integrating knowledge from other servers of large KBs is not easy but it is easier than integrating dozens or hundreds of (semi-)independently created small KBs. Furthermore, since in our approach the first integration from a server is loss-less, the subsequent integrations from this server are much easier. A more fundamental obstacle to the widespread use of this approach is that many industry-related servers are likely to make it difficult or illegal to mirror their KBs; however, this problem hampers all integration approaches. The above described replication mechanism is a way to combine the advantages commonly attributed to "distributed approaches" and "centralized approaches". The inadequacy of this terminology - and its related misconceptions - are thereby also highlighted: (i) not just "mostly independently created resources" can be distributed, and (ii) as shown by the next two sub-sections, "collaboratively editing a same KB" (i.e., centralization) does not imply that the users have to agree or even discuss terminological issues or beliefs, nor that a committee making content selection or conflict resolution for the users is necessary.
Most knowledge servers support concurrency control and users' permissions on files/KBs but WebKB-2 (Martin, 2003a) is the only knowledge server having editing protocols permitting and encouraging people to tightly interconnect their knowledge into a shared KB, without having to discuss and agree on terminology or beliefs, and while keeping the KB consistent. Co4 (Euzenat, 1996) had knowledge sharing protocols based on peer-reviewing for finding consensual knowledge: their output of which was a hierarchy of KBs, the uppermost ones containing the most consensual knowledge while the lowermost ones were the KBs of the contributing users. All other "protocols" used in knowledge portals (Lausen et al., 2005) or knowledge oriented approaches in peer-to-peer networks (Rousset, 2004) or Semantic Grids (Page et al., 2005) focus on managing the integration of some source KB into a private/shared target KB: these protocols are not guiding nor even permitting the users of the two involved KBs to tightly interconnect their knowledge. The next paragraph summarises the principles of WebKB-2's editing protocols.
Each category identifier is prefixed by a short identifier for the category
creator. Each creator is represented by a category and thus may have
associated statements. Each formal or informal statement also has an associated
creator and hence, if it is not a definition, may be considered as a belief.
Any object (category or statement) may be re-used by any user within her statements.
The removal of an object can only be done by its creator but a user may
"correct" a belief by connecting it to another belief via a
"corrective relation".
Definitions cannot be corrected since they cannot be false; for example, a
user such as "fg" is perfectly entitled to define fg#cat as a subtype of
the WordNet type wn#chair: there is no inconsistency as long as the ways
fg#cat is further defined or used respect the constraints associated
to wn#chair.
If entering a new belief introduces a redundancy or an inconsistency that is
detected by the system, it is rejected. The user may then either correct this
belief or re-enter it again but connected by specialization relations (e.g.
"example") or "corrective relations" (e.g., "corrective_generalization") to each
belief it is redundant or inconsistent with. For example, here is a
Formalized-English statement by Joe that corrects an earlier statement by John:
`any bird is agent of a flight'(John) has for corrective_restriction
`most healthy French birds are able to be agent of a flight' '(Joe).
The use of corrective relations allows and makes explicit
the disagreement of one user with (her interpretation of) the belief of another
user. This also technically removes the cause of the problem: a proposition A
may be inconsistent with a proposition B but a belief that
"A is a correction of B" is not technically inconsistent with a belief in B.
Choices between beliefs may have to be made for an
application, but then the explicit relations between beliefs can be exploited,
for example by always selecting the most specialized beliefs.
The above described recording of each object's creator, and the possibility for any user to represent information about each creator, permit to combine conceptual querying "by the content" with conceptual querying "on the creators". For example, WebKB-2 allows any user to set up filters on certain (kinds of) creators to avoid their knowledge being displayed during browsing or within query results. This is handy when certain users are not providing good quality knowledge and when this becomes a nuisance for exploring and comparing the objects of certain domains despite the conceptual organization of the KB and hence its limited amount of redundancies. However, to allow a much better filtering of knowledge and/or their sources, additional information on each statement and each statement creator need to be recorded and exploited: their originality, popularity, acceptation and other characteristics related to the "usefulness" of a statement or creator. In (Martin et al., 2006), we gave a template algorithm to quantify the usefulness of each statement in a KB, and then also on each of their creators, based on votes from users on statements and on how each statement is (counter-)argued using argumentation relations. To be even more useful, this algorithm should accept parameters permitting each user to specify her own view about which kinds of statements or users should be displayed and, if so, how. This approach eliminates the need for (i) allowing or forcing "special users" to perform some content selection in the KB for other users, thereby restricting the scope, goals and interest of the KB, or (ii) allowing any user to delete anything, as in wikis, which leads to edit wars. However, there is still a need for some special users to remove (or not) completely irrelevant statements (spam) that have been voted as such by some users and not prevented automatically. Given how our template algorithm attributes a usefulness value to each statement and each user, this approach should incite the users to be careful and precise in their contributions and give arguments for them: unlike in traditional discussions or reviews, a value for each statement can be given by the template algorithm and each user can refine the problematic statements to improve them and be rewarded. (With our template algorithm, using a different pseudo when providing low quality statements is not an effective turn-around strategy since this reduces the number of authored statements for other pseudos. When a belief is counter-argued, the usefulness of its author decreases, and hence she is incited to deepen the discussion or remove the faulty belief.)
In his description of a "Digital Aristotle", Hillis (2004) describes a "Knowledge Web" to which teachers and researchers could add "isolated ideas" and "single explanations" at the right place, and suggests that this Knowledge Web could and should "include the mechanisms for credit assignment, usage tracking, and annotation that the Web lacks" (pp. 4-5), thus supporting a much better re-use and evaluation of the work of a researcher than the current system of article publishing and reviewing. Hillis does not give any indication on such mechanisms but those proposed in this sub-section and the two previous ones seem a good basis. Other valuation and trust propagation mechanisms exist, e.g., those of Lewen et al. (2006) referred to in Section 2.1, but unfortunately (i) they are used on attribute-values representing/indexing the content of whole documents, not on the "usefulness" characteristics of precise statements, and (ii) they generally do not take argumentation relations into account. A primitive and informal version of our statement valuation approach was implemented in SYNVIEW (Lowe, 1985). Finally, we mentioned how Co4 allowed its users to evaluate how consensual their knowledge was.
To ease the automatic or manual comparison of objects within and between KBs, and hence also their retrieval, these objects should be represented as precisely and uniformly as possible. This implies easing and guiding knowledge entering by providing the users with at least the following supports, all of which should be designed to ease the adoption of knowledge modelling "best practices": 1) for each KB, a large well-organized ontology that integrates the various existing ontologies related to the scope of the KB, 2) knowledge entering/querying/entering interfaces exploiting these ontologies and hence dynamically generated from them, 3) expressive, intuitive and concise KRLs, and 4) parsers for simple natural language sentences that propose normalized representations for these sentences. Many complementary knowledge modelling methodologies (e.g., CommonKADS, Ontoclean, Methondology and On-To-Knowledge) and "best practice" rules exist but most of them are un-supported by all low-level KRLs (e.g., KIF, the Knowledge Interchange Format, and RDF, the Resource Description Format), by almost all other KRLs and ontologies and by most KB editors. Almost all the examples and ontologies officially related to the Semantic Web, including those provided by the W3C, ignore the lexical, structural and ontological best practices that we collected in (Martin, 2000). Some examples are given in Section 7. Only Point 2 of the above four points is not uncommon in advanced KB systems, as for example in SHAKEN (Chaudhri et al., 2001). CYC provides approximate solutions for the four points: it has a parser of English sentences (Witbrock et al., 2003), it has the biggest existing general KB and CycL (the KRL of CYC) is expressive albeit not very intuitive nor concise. However, CYC does not respect lexical, structural and ontological best practices; for example, because of CyCL, CYC often contains statements based on N-ary relations instead of using more explicit and matchable forms using binary relations. Furthermore, CYC does not store the sources of each object (e.g., its creator or a source in a document and the user that represented it into the KB) and does not have protocols to permit the update of the KB by any Web user.
As a step toward Point 1, we transformed WordNet into a genuine lexical ontology and complemented it with many top-level ontologies (Martin, 2003b) into WebKB-2. We have also begun an ontology of knowledge engineering (Martin et al., 2007) and we shall invite researchers and lecturers in this field to represent their ideas, tools and LOs when such additions will be sufficiently guided by the ontology and WebKB-2 to be made in a scalable manner. This means that we have to represent and organize the main tasks, data structures and technique characteristics in knowledge engineering. An ontology such as the Semantic Web Topics Ontology of ISWC 2006 is by no mean usable for knowledge representation and is not even scalable for document indexation since (i) it does not follow knowledge representation/sharing best practices, is not integrated into a lexical ontology, and updates should be suggested to its creators by email or via a wiki, and (ii) it is based on "topics" and uses quite vague relations such as topic_subtopic, topic_requires, topic_relatedTo and topic_relatedProjects, and hence does not permit the user to find "a right place" to insert a new concept - as noted by Welty & Jenkins (1999), placing a topic into a specialization hierarchy of topics is quite arbitrary, whereas a category for a task or a data structure has a unique correct place into a partOf/specializationOf hierarchy of tasks or data structures, given the intended formal meaning of the categories and the formal meanings of the used partOf/specializationOf relations.
As a step toward Point 3, WebKB-2 proposes notations such as "Formalized English" (FE), "Frame Conceptual Graphs" (FCG) and "For-Links" (FL; a sub-language of FCG when quantifiers need not be used). They are more high-level and compact than currently existing notations and often much more expressive too (Martin, 2002). High-level means intuitive and normalizing: the syntax of our notations includes many components (e.g., various extended quantifiers and collection "interpretations") that (i) would be very difficult for users to define correctly and in comparable or formally exploitable ways, (ii) make the syntax more English-like, and (iii) lead the users to follow best practices and hence provide more precise and automatically comparable knowledge, thus, more retrievable and checkable for redundancies and inconsistencies. More compact means that more knowledge can be displayed in a structured way in a short amount of space, which is very important to ease the manual retrieval and comparison of knowledge in a large KB. This is one of the reasons why KB systems should allow the entering, querying, display and browsing of knowledge using textual notations in addition to graphic notations. The following tables show examples of simple representations in FE, FCG and FL, languages that we are still extending. RDF translations of them would be long and ad-hoc. We packed many details into these examples and we invite the reader to really delve into these details in order to get a better intuition of the proposed approach.
E: According to the user with identifier "jo", (i) any human body has at most 2 arms
and exactly 1 head, and (ii) most arms belong to at most 1 human body.
According to "pm", male_body and female_body are exclusive subtypes of human_body,
and most human bodies have legs.
According to "oc", most human_bodies are able to sleep for 12 hours.
FL: human_body part: arm [any->0..2(jo), 0..1<-most(jo)] head [any->1(jo)] leg [most->0..*(pm)],
subtype: excl{ male_body(pm) female_body(pm) }(pm),
can be agent of: [(sleep, period: 12 hour)][most->a(oc)];
/* This last line could also be written:
agent of: [(sleep, period: 12 hour)][most->a(oc, modality: can)];
agent of: (sleep period: hour [a->12]) [most->a (oc, modality: can)];
These last two forms are used for printing because the relation type does not have to be
printed again if other relations from the source have the same type (other advantage:
the destination of these relations can be printed on the same line).
This last line could also be written separately in FCG:
[most human_body, can be agent of: (a sleep, period: 12 hours)] */
|
E: According to "jo", most human_body (as understood in WordNet 1.7)
may have for part (as understood by "pm") one or two legs (as defined by "fg")
and have exactly 1 head (as understood by "oc").
FL: wn#body pm#part: 0..2 fg#leg (jo) 1 oc#head (jo);
FE: `most wn#body pm#part at most 2 fg#leg and for pm#part 1 oc#head'(jo);
FCG: [most wn#body, pm#part: at most 2 fg#leg, pm#part: 1 oc#head](jo);
KIF: (believer '(forall ((?b wn#body)) (atMostN 2 '?l fg#leg (pm#part '?b ?l))) jo)
(believer '(forall ((?b wn#body)) (exactlyN 1 '?h oc#head (pm#part '?b ?h))) jo)
|
"knowledge_sharing_with_an_XML-based_language is advantageous"
extended_specialization of: "knowledge_sharing_with_an_XML-based_language is possible" (pm),
specialization: ("knowledge_sharing_on_the_Web_with_an_XML-based_language
is advantageous"
argument of: "the Semantic Web should have an XML notation" (pm)
)(pm),
argument: - "XML is a standard" (pm)
- ("knowledge_management_with_classic_XML_tools is possible"
corrective_restriction:
"syntactic_knowledge_management_with_classic_XML_tools is possible" (pm,
argument: ("there is no exploitation_of_semantics by classic_XML_tools"
example: "there is no taking_into_account by classic_XML_tools
of the fact that RDF/XML has multiple equivalent
serialisations" (pm)
)(pm) )
)(pm),
argument: "the use of URIs and Unicode is possible in XML"
(fg, objection: "the use of URIs and Unicode can easily be made possible
in most syntaxes" (tbl, pm) //according to pm, the last
//statement is an objection by Tim Berners Lee on F.G.'s
//argument (the use of the relation, not its destination)
),
objection: - ("the use_of_XML_by_KBSs implies several tasks to manage"
argument: "the internal_model_of_KBSs is rarely XML" (pm)
)(pm)
- ` "an increase of the number of tasks *t to_manage" has for consequence
"an increase of the difficulty to develop a software to manage *t" ' (pm),
objection: - "knowledge_sharing_with_an_XML-based_language forces
many persons (developers, specialists, etc.) to understand
complex_XML-based_knowledge_representations" (pm)
- ("understanding complex_XML-based_knowledge_representations is difficult"
argument: "XML is verbose" (pm)
)(pm);
|
We have used FL to represent the content of three courses at Griffith Uni: "Workflow Management", "Systems Analysis & Design", and "Introduction to Multimedia". Nearly each sentence of each slide for these courses has been represented into a semantic network of tasks, data structures, properties, definitions, etc. The students of these courses have recognised the help that the semantic network provides them in relating and comparing information otherwise scattered in many different slides and other lecture materials. Having to learn FL was however perceived as a problem, especially by the students who were evaluated on their contributions to the semantic network (Martin, 2006). An intuitive table-based knowledge entering/display interface for FL should reduce this problem.
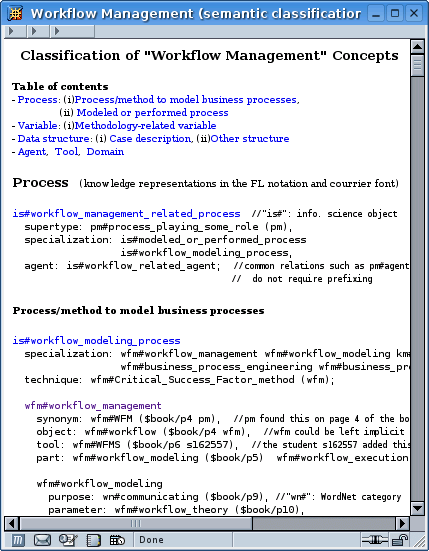
Figure 1 - Extract from a file representing statements from a book in Workflow Management (here referred to by the variable $book). Any Web user can create such a file and ask WebKB-2 to parse it and hence integrate its knowledge representations into the shared KB.
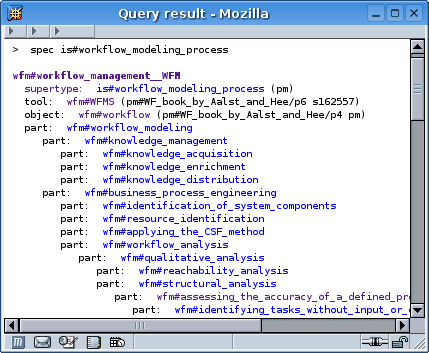
Figure 2 - a search for the specializations of a statement in FCG and its first result (clicking on wfm#workflow_management returns the same result, here displayed in an informal format looking like FL).
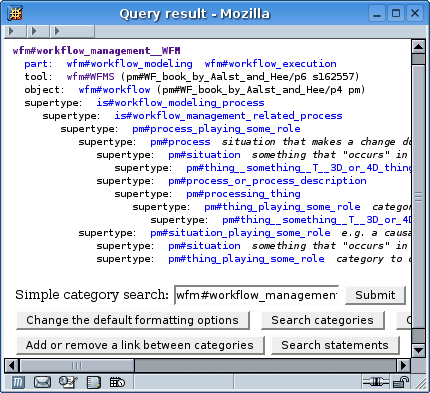
Figure 3 - Expansion of the supertypes of wfm#workflow_management.
Nowadays, many businesses grow or merge to stay competitive, and de-facto standards tend to persist despite their widely recognized shortcomings, especially in information technology. The KB and knowledge sharing conventions or mechanisms of the first company that will propose a general KB that people will be able to update in a somewhat organized way are likely to quickly become de-facto standards in the same way that the Web, Google and Wikipedia quickly became widely used. Given current knowledge sharing pratices, it is unfortunately unlikely that this initial KB and chosen conventions or mechanisms will be the best ones for scalability purposes. In any case, this KB will be collaboratively updated by all kinds of persons (researchers, lecturers, students, company employees, etc.) and purposes (storing LOs, advertising or giving feedbacks on products, etc.). Indeed, we have shown that a KB server can be used by many people for collaboratively organizing and valuating knowledge at various levels of details, and that alternative technologies are less efficient for sharing and retrieving information.
One hypothesis behind our approach is that a sufficient number of persons will take the time to be precise and learn notations and conventions to do that. We do not think this will be a problem once the approach becomes popular with researchers, teachers and students, and we concluded in Section 2.2 that this was likely to happen. The social success of Wikipedia shows that despite its problems many persons are willing to contribute, and our approach would solve these problems. In this approach people can engage in "structured discussions" by connecting statements via argumentation/corrective relations, thereby not only representing debates in unprecedentedly structured ways but are also collaboratively evaluating themselves on each of their statements; this intellectual challenge and opportunity for recognition may attract a lot of people. More generally, this approach is in-line with the constructivist and argumentation theories and can be seen as a particular implementation and support of the "critical thinking" theories approaches and Brandom's model of discursive practice (Brandom, 1998).
We argued that a virtual global normalised well-organized collaboratively-updated formal and semi-formal KB is necessary and achievable for the scalable and efficient sharing and retrieval of LOs or other kinds of information within intranets or on the internet, and therefore as a shared medium for the tasks of publishing, researching, teaching, learning, annotating, evaluating and collaborating. In comparison, synchronous approaches (e.g., on-line chats and face-to-face teaching) and approaches based on indexing or relating formal or informal documents or KBs, are extremely sub-optimal for information publishing, retrieval, comparison and learning. Ideally, a normalized KB is like a decision tree: the place or way to insert or find information is quickly found, however huge the KB, and the existing information (fact, hypothesis, feedback, etc.) can be incrementally completed or refined. Documents often do not contain precise enough information to create such a KB directly from them; the proposed approach leads information providers to deepen and structure their knowledge and permits to evaluate or filter out each of the individual contributions. Automatic knowledge extraction, alignment or merging methods are needed to help building this KB but need to be adapted to take into account knowledge sharing best practices and used for combining the advantages of centralisation and distribution rather than just creating new resources. Documents and synchronous collaboration or teaching will always exist and be needed but these works will hopefully also lead to the completion of more semantically structured media and hence permit other people to easily find and re-use the results of these works.
Brandom, R. (1998). Action, Norms, and Practical Reasoning. Noûs, Volume 32, Supplement 2, pp. 127-139.
Buckingham-Shum, S., Motta, E., & Domingue, J. (1999). Representing Scholarly Claims in Internet Digital Libraries: A Knowledge Modelling Approach. In ECDL'99 (pp. 423-442), Paris, France.
Chaudhri, V., Rodriguez, A., Thoméré, J., Mishra, S., Gil, Y., Hayes, P., et al. (2001). Knowledge entry as the graphical assembly of components. In K-Cap'01 (pp. 22-29), British Columbia, Canada.
Devedzic, V. (2004). Education and the Semantic Web. International Journal of Artificial Intelligence in Education, 14, pp. 39-65.
Downes, S. (2001). Learning Objects: Resources For Distance Education Worldwide. International Review of Research in Open and Distance Learning, Vol. 2, No.1.
Euzenat, J. (1996). Corporate memory through cooperative creation of knowledge bases and hyper-documents. In KAW 1996, (36)1-18, Banff, Canada.
Euzenat, J., Stuckenschmidt, H., & Yatskevich, M. (2005). Introduction to the Ontology Alignment Evaluation 2005. In K-Cap'05 (pp. 61-71) Banff, Canada.
Euzenat, J. (2005). Alignment infrastructure for ontology mediation and other applications. In ICSOC'05 (pp. 81-95), Amsterdam, Netherlands.
Friedland, N.S, Allen, P., Mathews, G., Witbrock, M., Baxter, D., Curtis, J., et al. (2004). Project Halo: Towards a Digital Aristotle. AI Magazine, 25(4), pp. 29-48.
Gouardères, G., Saber, M., Nkambou, R., & Yatchou, R. (2005). The Grid-E-Card: Architecture to Share Collective Intelligence on the Grid. Applied Artificial Intelligence, Vol. 19, No. 9-10, pp. 1043-1073.
Hillis, W.D. (2004). "Aristotle" (The Knowledge Web). Edge Foundation, Inc., No 138, May 6.
Hodgins, W. (2006). Out of the past and into the future: Standards for technology enhanced learning. In U. Ehlers and J. Pawlowski (Eds.), Handbook on Quality and Standardisation in E-Learning. (pp. 309-327). Springer Berlin Heidelberg.
IEEE LTSC (2001). IEEE Learning Technology Standards Committee Glossary. IEEE P1484.3 GLOSSARY WORKING GROUP, draft standard 2001.
Lausen, H., Ding, Y., Stollberg, M., Fensel, D., Lara, R., & Han, S. (2005). Semantic web portals: state-of-the-art survey. Journal of Knowledge Management, Vol. 9, No. 5, pp. 40-49.
Lewen, H., Supekar, K.S., Noy, N.F., & Musen M.A. (2006). Topic-Specific Trust and Open Rating Systems: An Approach for Ontology Evaluation. In EON'06 at WWW'06, Edinburgh, UK.
Lowe, D. (1985). Co-operative Structuring of Information: The Representation of reasoning and debate. International Journal of Man-Machine Studies, 23(2), pp. 97-111.
Martin, P. (2000). Conventions and Notations for Knowledge Representation and Retrieval. In ICCS'00 (pp. 41-54), Springer-Verlag, LNAI 1867.
Martin, P. (2002). Knowledge representation in CGLF, CGIF, KIF, Frame-CG and Formalized-English. In ICCS'02 (pp. 77-91) Springer-Verlag, LNAI 2393.
Martin, P. (2003a). Knowledge Representation, Sharing and Retrieval on the Web. In N. Zhong, J. Liu and Y. Yao (Eds.), Web Intelligence (pp. 263-297), Springer-Verlag.
Martin, P. (2003b). Correction and Extension of WordNet 1.7. In ICCS 2003 (pp. 160-173), Springer-Verlag, LNAI 2746.
Martin, P., Eboueya, M., Blumenstein, M., & Deer P. (2006). A Network of Semantically Structured Wikipedia to Bind Information. In E-learn'06 (pp. 1684-1702), Honolulu, Hawaii.
Martin, P. (2006). Griffith E-Learning Fellowship Report. Retrieved July 2, 2007, from http://www.webkb.org/doc/papers/GEL06/
Martin, P., & Eboueya, M. (2007). Sharing and Comparing Information about Knowledge Engineering. WSEAS Transactions on Information Science and Applications, 5(4), pp. 1089-1096, May 2007. ICCS 2003, 11th International Conference on Conceptual Structures (Springer Verlag, LNAI 2746, pp. 362-377), Dresden, Germany, July 21-25, 2003. -->
Noy, N.F., Chugh, A., Liu, W., & Musen, M. A. (2006). A framework for ontology evolution in collaborative environments. In ISWC'06 Athens, GA.
Novak. J.D. (2004). Reflections on a Half Century of Thinking in Science Education and Research: Implications from a Twelve-year Longitudinal Study of Children's Learning. Canadian Journal of Science, Mathematics, and Technology Education, 4(1): 23-41.
Page, K., Michaelides, D., Buckingham-Shum, S., Chen-Burger, Y., Dalton, J., De Roure, et al. (2005). Collaboration in the Semantic Grid: a Basis for e-Learning. Journal of Applied Artificial Intelligence, 19(9-10), pp. 881-904.
Rousset, M-C. (2004). Small Can Be Beautiful in the Semantic Web. In ISWC'04 (pp. 6-16).
Sanger, L.M. (2006) The Future of Free Information. Digital Universe Electronic Journal, 2006-01. Retrieved July 2, 2007, from http://www.dufoundation.org/downloads/Article_2006_01.pdf
Shadbolt, N., Berners-Lee, T. & Hall, W. (2006). The Semantic Web Revisited. IEEE Intelligent Systems, 21(3) pp. 96-101.
Schuler, W., & Smith, J.B. (1992). Author's Argumentation Assistant (AAA): A Hypertext-Based Authoring Tool for Argumentative Texts. In Hypertext: concepts, systems and applications (pp. 137-151), Cambridge University Press.
Shipman, F.M., & Marshall, C.C. (1999). Formality considered harmful: experiences, emerging themes, and directions on the use of formal representations in interactive systems. Computer Supported Cooperative Work, 8, pp. 333-352.
Swick, R., Schreiber, G., & Wood, D. (2006) Semantic Web Best Practices and Deployment Working Group. Retrieved July 2, 2007, from http://www.w3.org/2001/sw/BestPractices/
Sowa, J.F. (2006). Concept Mapping. Retrieved July 2, 2007, from http://www.jfsowa.com/talks/cmapping.pdf
Stutt, A. & Motta, E. (2004). Semantic Learning Webs. Journal of Interactive Media in Education, Special Issue on the Educational Semantic Web, 10.
Vrandecic, D., Pinto, H.S., Sure, Y. & Tempich, C. (2005). The DILIGENT Knowledge Processes. Journal of Knowledge Management, 9(5), pp. 85-96.
Welty, C.A. & Jenkins, J. (1999). Formal Ontology for Subject. Journal of Knowledge and Data Engineering, 31(2), pp. 155-182.
Witbrock, M., Baxter, D., Curtis, J., Schneider, D., Kahlert, R., Miraglia, P., et al. (2003). An Interactive Dialogue System for Knowledge Acquisition in Cyc. In IJCAI'03 (pp. 138-145), Acapulco, Mexico.